DEPRECATION WARNING
This documentation is not using the current rendering mechanism and is probably outdated. The extension maintainer should switch to the new system. Details on how to use the rendering mechanism can be found here.
EXT: robots.txt for multidomain¶
| Created: | 2010-02-18T17:33:18 |
|---|---|
| Changed: | 2014-04-27T11:58:51.980000000 |
| Classification: | dev_null_robots |
| Keywords: | robots, robots.txt, multidomain |
| Author: | Wolfgang Rotschek |
| Email: | scotty@dev-null.at |
| Info 4: | |
| Language: | en, de |

 EXT: robots.txt for multidomain - dev_null_robots
EXT: robots.txt for multidomain - dev_null_robots
EXT: robots.txt for multidomain¶
Extension Key: dev_null_robots
Language: en, de
Keywords: robots, robots.txt, multidomain
Copyright 2011, Wolfgang Rotschek, <scotty@dev-null.at>
This document is published under the Open Content License
available from http://www.opencontent.org/opl.shtml
The content of this document is related to TYPO3
- a GNU/GPL CMS/Framework available from www.typo3.org
Table of Contents¶
EXT: robots.txt for multidomain 1
`Introduction 3 <#__RefHeading__939_1075929538>`_
What does Dev/Null Robots.txt do? 3
`Users manual 4 <#__RefHeading__953_1075929538>`_
`Administration 5 <#__RefHeading__957_1075929538>`_
`Domain Record Configuration 6 <#__RefHeading__1218_1613841388>`_
`Crawler-specific Configuration 7 <#__RefHeading__1224_1613841388>`_
`Page Meta Tags 8 <#__RefHeading__634_1224899791>`_
`Configuration 9 <#__RefHeading__961_1075929538>`_
Output Defaults for robots.txt (useDefaults) 9
`Known problems 10 <#__RefHeading__967_1075929538>`_
`To-Do list 11 <#__RefHeading__971_1075929538>`_
`ChangeLog 12 <#__RefHeading__973_1075929538>`_
Introduction¶
What does Dev/Null Robots.txt do?¶
This extension generates domain specific robots.txt files. Configuration is done from in sys_domain records and typoscript.
Features¶
- Preconfigured TS-Templates for robots.txt
- Different robots.txt per domain
- Supports RealURL auto-configuration
Credits¶
Automate RealURL configuration where possible – Jacob Floyd < jacob@cognifire.com >
Users manual¶
- Download and install the extension with the extension manager
- Configure URL-rewriting for your robots.txt (as necessary)
Usage¶
This extension works nearly out of the box, especially if you use RealURL with automatic configuration. If you don't have that, then only URL-rewriting has to be configured. (See the Administration section for help configuring URL-Rewriting)
Assuming your website starts with id=1, make sure your robots.txt is working with the following url:
http://www.yourdomain.tld/index.php?id=1&type=1964
Next, configure URL-rewriting for each domain, as necessary. (See Administration )
[Optional] Add additional robots.txt configuration in domain records.
(See Domain Record Configuration and Crawler-specific Configuration )
When you're done, make sure that it works by visiting: http://www.yourdomain.tld/robots.txt
[Optional] Add any page specific meta-data (See Page Meta Tags )
((generated))¶
Example¶
You can see a working robots.txt at: http://www.dev- null.at/robots.txt
Administration¶
The extension is pre-configured to output a robots.txt whenever page type 1964 is requested. If your Templates already use type 1964, you can change the default value of typeNumin the Constant Editor. To get to the Constant Editor, go to the root of your website, edit the template, and choose “Constant Editor” from the drop down. Just remember, if you change the default typeNum, you must also manually configure your url-rewriting solution.
Depending on your chosen URL-rewriting method, you may also have to configure rewriting the robots.txt file for each domain.
Check out the following sections for configuration instructions for Cooluri, RealURL and .htaccess.
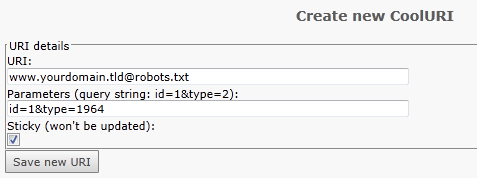
Cooluri¶
If you use the extension Cooluri for URL-rewriting you have to define the link for each domain that should serve a robots.txt
RealURL¶
If you use RealURL's automatic configuration, you're in luck; RealURL auto-configuration is supported out of the box. You may have to delete your realurl_autoconf.php file in typo3conf to get RealURL to regenerate it.
However, you must manually update your RealURL configuration if: (a) you have customized your RealURL re-writing configuration; or (b) you have changed the default typeNum setting. To manually make RealURL serve your robots.txt, add the following to your RealURL configuration (see the RealURL documentation for details on how to do this). The default configuration puts this block in the 'fileName' part of the configuration array.
'index' => array(
'robots.txt' => array(
'keyValues' => array(
'type' => '1964',
),
),
Remember: If you change your typeNum you have to change it here too!
.htaccess¶
This method is not recommended. It does not work in conjunction with RealURL, and n it hasn't been tested in any other siituations. You may have to create a rewrite rule for each domain.
RewriteCond %{HTTP_HOST} www.yourdoman.tld
RewriteRule ^(robots\.txt)$ index.php?id=1&type=1964 [L,NC]
RewriteRule .* index.php [L]
### End: Rewrite stuff ###
Domain Record Configuration¶
Domain records get two new fields: “crawler config list” and “Default crawler directives”.
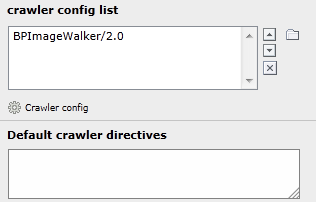
Crawler Config List¶
List of crawler specific configurations. This will be inserted before the default configuration.
Default Crawler Directives¶
Default Disallow and Allow statements without User-agent. To disallow all for the given domain just enter
Disallow: /
Crawler-specific Configuration¶
Default crawler configurations can be linked to domain records. Each crawler configuration has two fields:
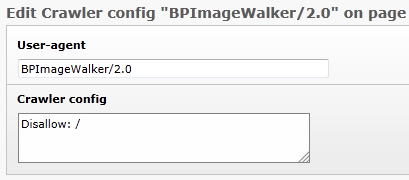
User-agent¶
Field
User-agent
Description
String which identifies the crawler.
Crawler config¶
Field
Crawler config
Description
Configuration for the crawler.
Page Meta Tags¶
Additional or alternately you can add robots meta tags to each page. You can setup the default behavior through the constants editor.
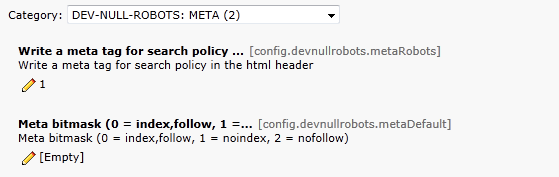
Within the page on the register metadata you can limit the robots for the page.
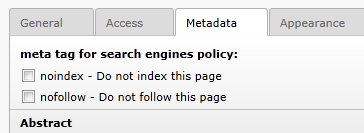
The restrictions from the typo script setup and the page record are merged. This means a noindex in the setup is reflected on all pages even if the checkbox is unchecked.
Configuration¶
You can configure the defaults for this extension by modifying the config.devnullrobotsTyposcript object. You can override these defaults on a per-domain basis, by modifying the appropriate fields in your sys_domain record(s).
Reference¶
useDefault¶
Property
useDefault
Data type
option
Description
String option which default configuration from the TS-template has to be used.
off no default configuration will be added
allow use config.devnullrobots.defaultRules.defaultAllow
disallow use config.devnullrobots.defaultRules.defaultDisallow
useDefault is ignored when a domain record provides its own configuration.
Default
allow
sitemapName¶
Property
sitemapName
Data type
string
Description
If set, a Sitemap :directive will be written at the and of the robots.txt
Default
sitemap.xml
metaRobots¶
Property
metaRobots
Data type
bool
Description
If set, a robots meta tag will be written into the pages header
Default
0
metaDefault¶
Property
metaDefault
Data type
int
Description
Bitmask for robots meta tag
0 index,follow
1 noindex,follow
2 index,nofollow
3 noindex,nofollow
Default
0
typeNum¶
Property
typeNum
Data type
int
Description
typeNum for the TS-page object, responsible for the robots.txt file
Default
1964
[tsref:config.devnullrobots]
Output Defaults for robots.txt (useDefaults)¶
((generated))¶
Default 'allow' output¶
This is the default Robots.txt output when useDefault = allow. If you would like to create your own defaults to be used across all of the sites in your TYPO3 install, modify config.devnullrobots.defaultRules.defaultAllowin your TS-Template.
User-agent: *
Disallow: /fileadmin
Disallow: /t3lib
Disallow: /typo3conf
Disallow: /typo3temp
Allow: /fileadmin/media
Default 'disallow' output¶
This is the default Robots.txt output when useDefault = disallow. If you would like to create your own defaults to be used across all of the sites in your TYPO3 install, modify config.devnullrobots.defaultRules.defaultDisallowin your TS-Template.
User-agent: *
Disallow: /
Known problems¶
Extension must be loaded after extension sourceopt
Feature request & Bugs¶
If you find a bug or a missing feature, please add it to the bugtracker of the extension at forge.
The address is:
http://forge.typo3.org/projects/extension-dev_null_robots/issues
For posting a bug or feature request you need an account of typo3.org.
You can see this extension in operation on one of my websites
To-Do list¶
ChangeLog¶
2.0.0¶
Version
2.0.0
Changes
Typo3 6.2 compatibility
1.4.0¶
Version
1.4.0
Changes
Added version dependency information
Tested with Typo3 4.5, 4.7, 6.0
1.3.0¶
Version
1.3.0
Changes
Added RealURL Auto-configuration – thanks to Jacob Floyd
1.2.0¶
Version
1.2.0
Changes
Site root doesn’t need to be on topmost level within pagetree anymore
1.1.1¶
Version
1.1.1
Changes
Added german translation – thanks to Bernhard Eckl
Added manual section for robot meta tagsReformatted manual
1.1.0¶
Version
1.1.0
Changes
Support for meta tags
Support for sitemap directive in robots.txt
1.0.1¶
Version
1.0.1
Changes
Added documentation for RealURL