File No-Index
- Extension key
-
file_noindex
- Package name
-
bm1/file-noindex
- Version
-
main
- Language
-
en
- Author
-
Phillip Baumgärtner & contributors
- License
-
This document is published under the Open Publication License.
- Rendered
-
Tue, 16 Jun 2026 12:35:34 +0000
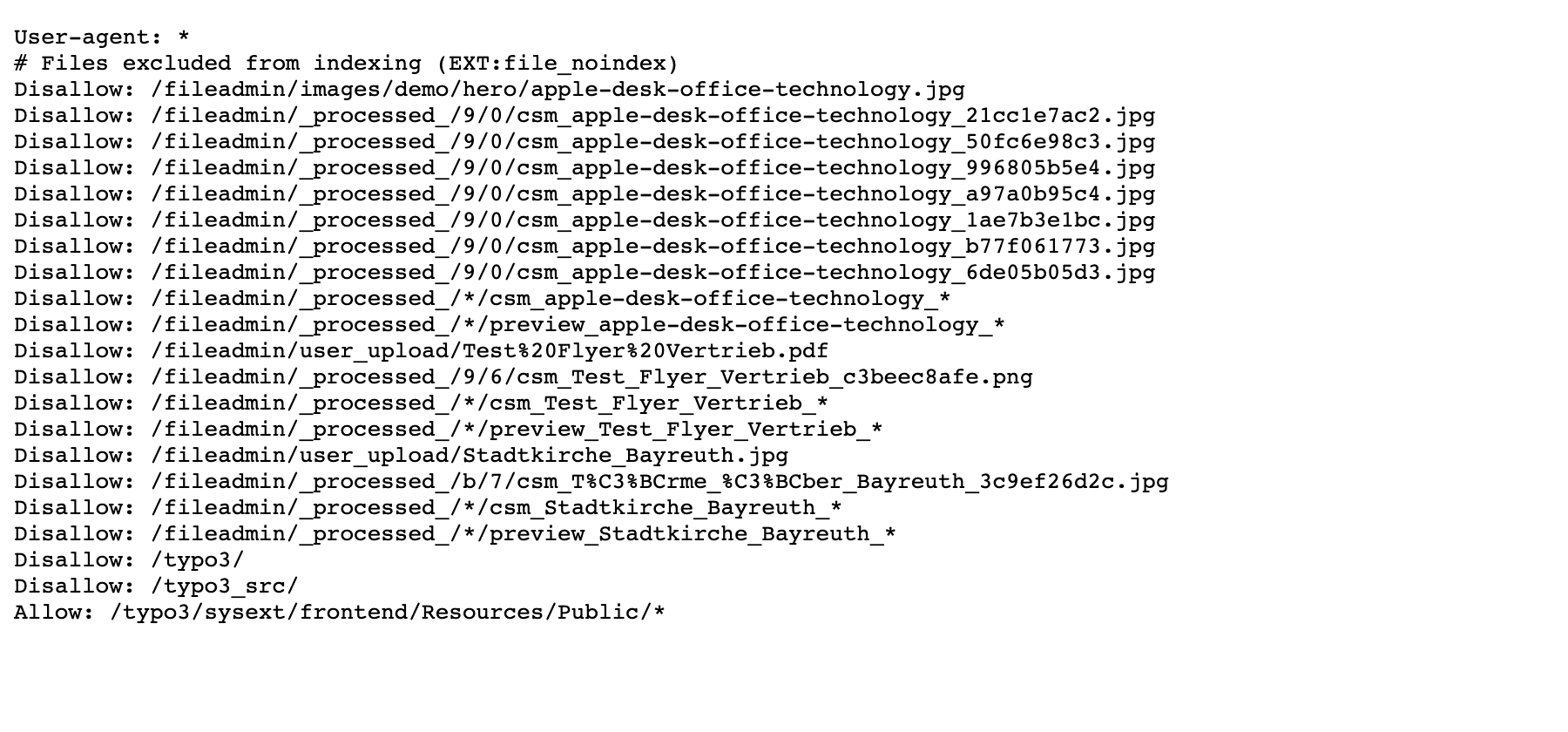
Editors can exclude any file (images of all kinds, PDFs, …) from search engine indexing directly in the File list module — one checkbox in the file metadata, no matter where the file is used and without a developer.
The extension serves a dynamically generated robots. that contains
Disallow entries for every marked file — the original file plus its
processed variants. Blocking via robots. is the
way officially recommended by Google
to keep images out of Google Image Search.
Table of contents: