This document is published under the
CC BY 4.0 license.
Rendered
Sun, 05 Jul 2026 12:40:52 +0000
Shared AI foundation for TYPO3. Configure LLM
providers once — every AI extension uses them.
Supports OpenAI, Anthropic Claude, Google Gemini,
Ollama, and more.
The Admin Tools > LLM backend module.
Getting started
📘 Introduction
Learn what nr-llm is, which providers are
supported, and what problems it solves.
📦 Installation
Install nr-llm via Composer and activate it.
For administrators
Set up and manage AI providers, models, and
configurations through the TYPO3 backend module.
🛠️ Administration guide
Step-by-step: add providers, fetch models,
create configurations and tasks. Includes
screenshots of every screen.
✨ AI-powered wizards
Setup wizard, configuration wizard, and
task wizard — let AI generate your config
from a plain-language description.
📋 Configuration reference
Complete field reference for providers,
models, configurations, TypoScript settings,
security, and caching.
For developers
Build your TYPO3 extension on nr-llm — three lines
of dependency injection, no API key handling.
🚀 Integration guide
Step-by-step tutorial: add AI capabilities
to your extension in five minutes.
💻 Developer guide
LlmServiceManager API, streaming, tool
calling, and custom providers.
⚙️ Feature services
Translation, vision, embeddings, and
completion — ready to inject and use.
📚 API reference
Complete class and method reference for
all public services and response objects.
🏗️ Architecture
Three-tier configuration hierarchy,
provider abstraction, and design decisions.
✅ Testing
Test infrastructure, mocking LLM services,
and CI configuration.
[n] A Netresearch extension
Professional TYPO3 development, AI integration,
and enterprise consulting since 2002.
nr-llm is the shared AI foundation for TYPO3.
It lets administrators configure LLM providers
once in the backend — and every AI-powered
extension on the site uses them automatically.
For extension developers, it eliminates the
need to build provider integrations, manage API
keys, or implement caching and streaming. Add AI
capabilities to your extension with three lines
of dependency injection.
For administrators, it provides a single backend module to manage all AI
connections, encrypted API keys, and provider
configurations. Switch from OpenAI to Anthropic
without touching any extension code.
For agencies, it means consistent AI architecture across client projects, no
vendor lock-in, and a local-first option via
Ollama for data-sensitive environments.
The extension enables developers to:
Access multiple AI providers through a single, consistent API.
Switch providers transparently without code changes.
Leverage specialized services for common
AI tasks (translation, vision, embeddings).
Cache responses to reduce API costs and improve performance.
Stream responses for real-time user experiences.
Store API keys securely as nr-vault
identifiers (envelope encryption).
The extension creates the following database tables automatically:
Table
Purpose
tx_nrllm_provider
Stores API provider connections with encrypted credentials.
tx_nrllm_model
Stores available LLM models with capabilities and pricing.
tx_nrllm_configuration
Stores use-case-specific configurations with prompts and parameters.
tx_nrllm_task
Stores one-shot prompt tasks for common operations.
tx_nrllm_prompttemplate
Stores reusable prompt templates with versioning
and performance tracking.
tx_nrllm_service_usage
Tracks specialized service usage (translation, speech, image).
Run the database compare tool after installation:
Set up extension database tables
vendor/bin/typo3 extension:setup nr_llm
Copied!
Cache configuration
The extension uses TYPO3's caching framework. Cache
configuration is set up automatically — no backend
is hardcoded. TYPO3 uses your instance's default
cache backend, so Redis, Valkey, or Memcached work
transparently if configured.
To override the cache backend specifically for nr-llm:
Remove any TypoScript includes referencing the extension.
Administration
This guide walks you through managing AI providers,
models, configurations, and tasks in the TYPO3
backend. It also covers the AI-powered wizards that
automate most of the setup.
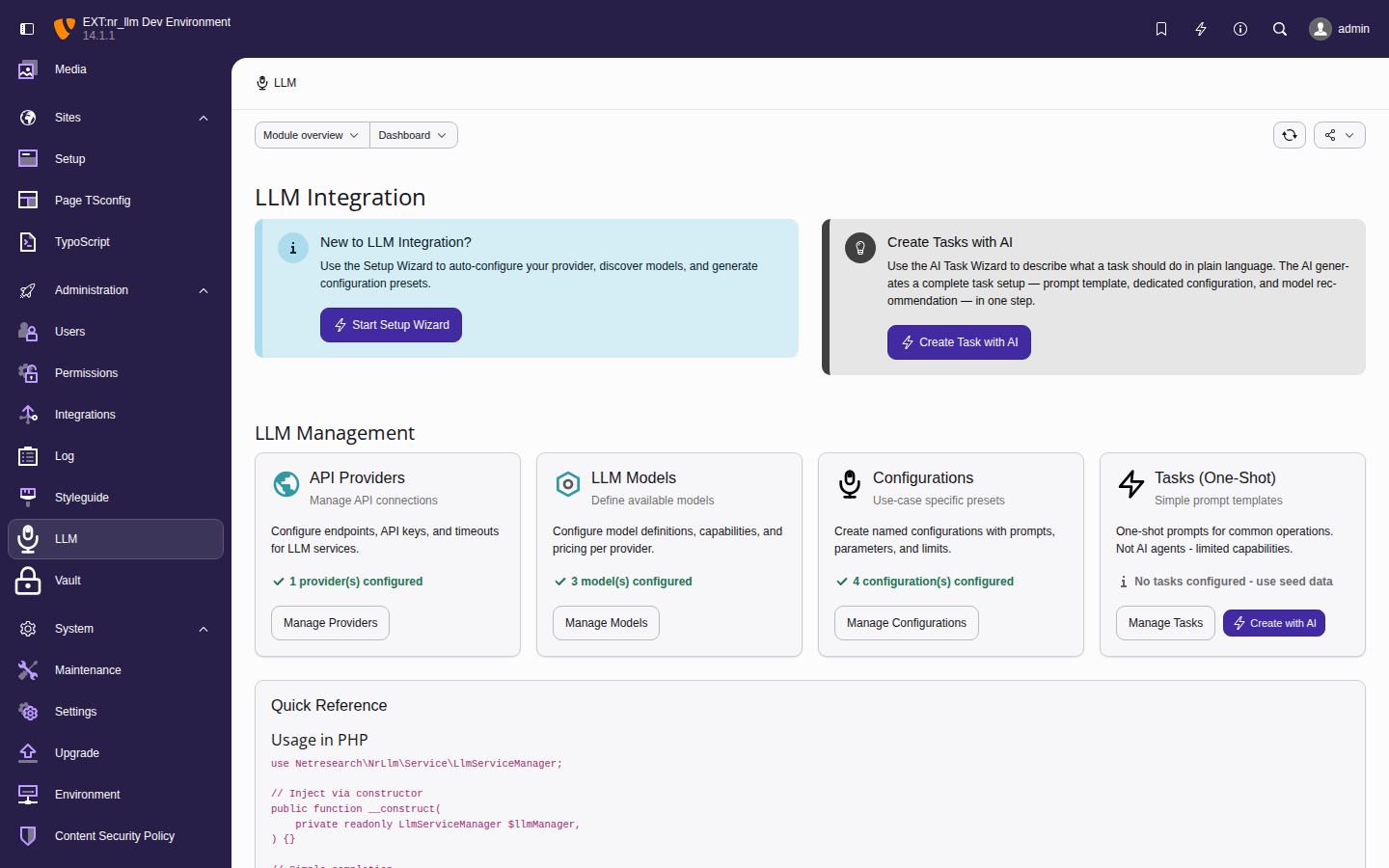
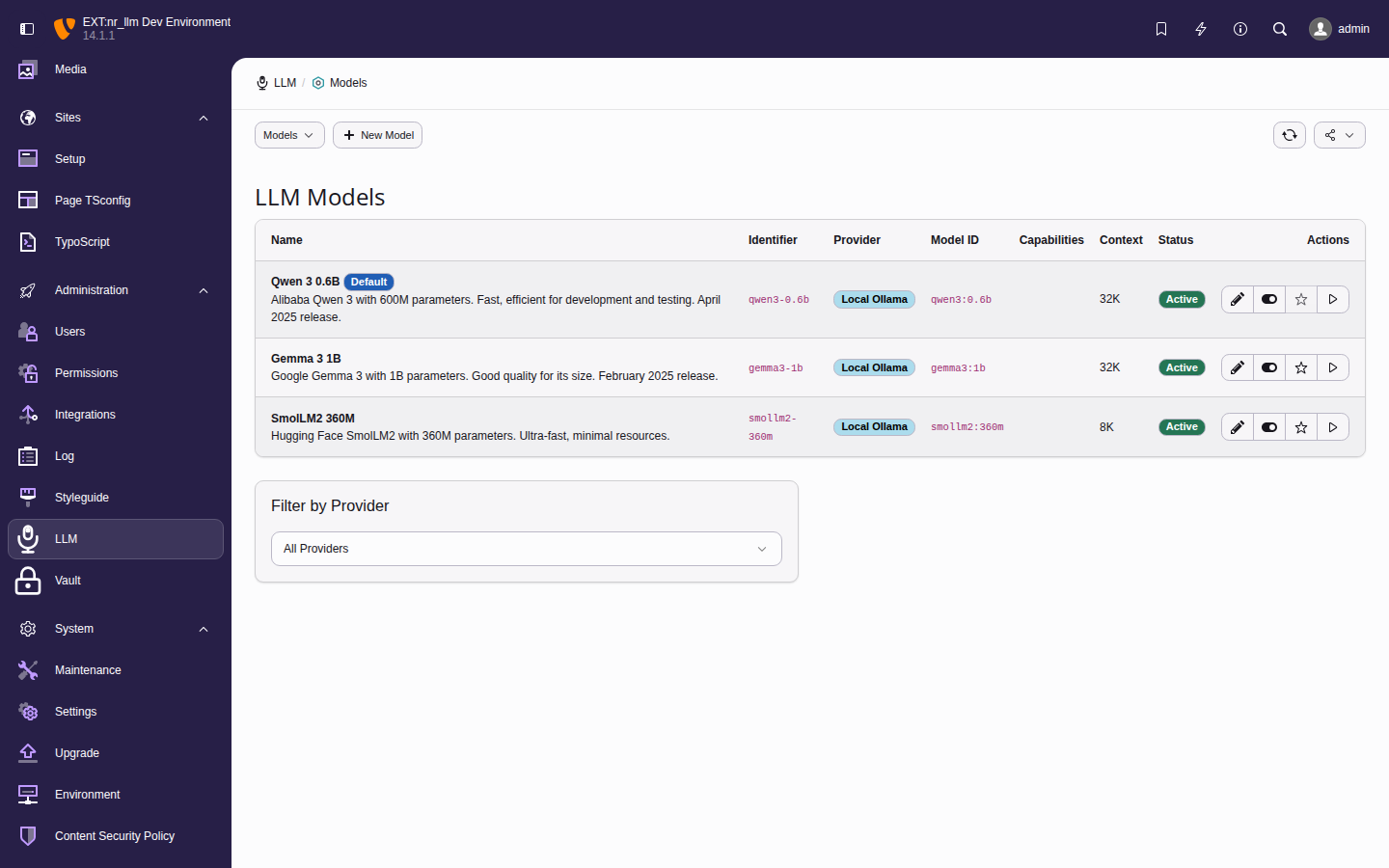
The LLM backend module
All AI management happens in
Admin Tools > LLM. The dashboard shows
your current setup status, quick links to each
section, and AI wizard buttons.
The LLM dashboard with setup progress, wizard
buttons, and quick-reference PHP snippets.
The module has eleven sections accessible from the
left-hand navigation:
Dashboard — overview and wizards
Providers — API connections
Models — available LLM models
Configurations — use-case presets
Tasks — one-shot prompt templates
Snippets — tagged reusable prompt fragments
Setup wizard — guided provider, model and configuration setup (admin-only)
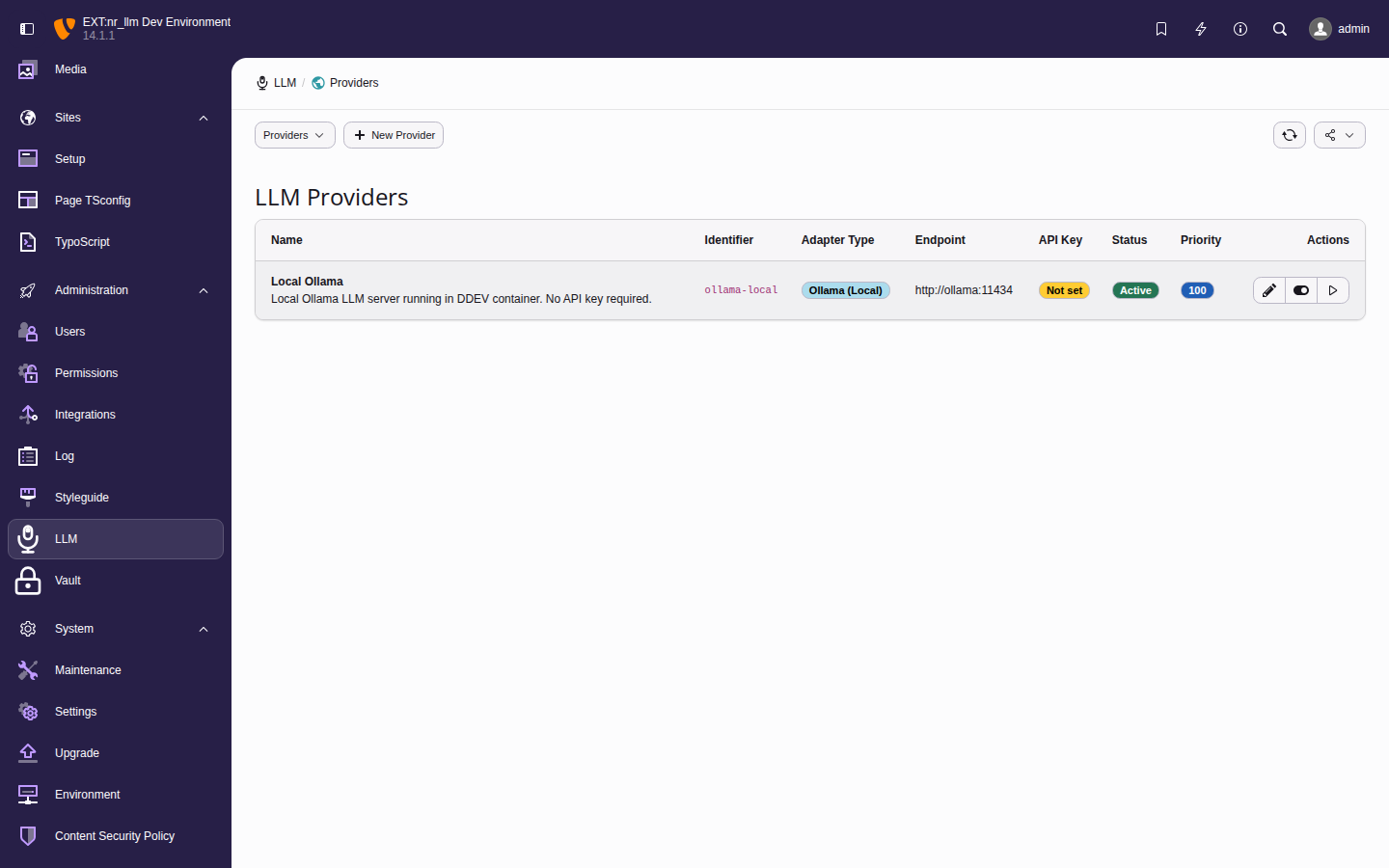
Providers represent connections to AI services.
Each provider stores an API endpoint, encrypted
credentials, and adapter-specific settings.
The provider list with connection status
indicators and action buttons.
Adding a provider
Navigate to Admin Tools > LLM >
Providers.
Click Add Provider.
Fill in the required fields:
Identifier
A unique slug for programmatic access
(e.g., openai-prod, ollama-local).
Name
A display name for the backend
(e.g., OpenAI Production).
Adapter Type
Select the provider protocol. Available
adapters: openai, anthropic,
gemini, ollama, openrouter,
mistral, groq, azure_openai,
custom.
API Key
Your API key. Stored securely via
nr-vault
envelope encryption. Leave empty for local
providers like Ollama.
Optionally set the endpoint URL, organization
ID, timeout, and retry count.
Click Save.
Tip
Use the Setup wizard for guided
first-time setup — it auto-detects the provider
type from your endpoint URL.
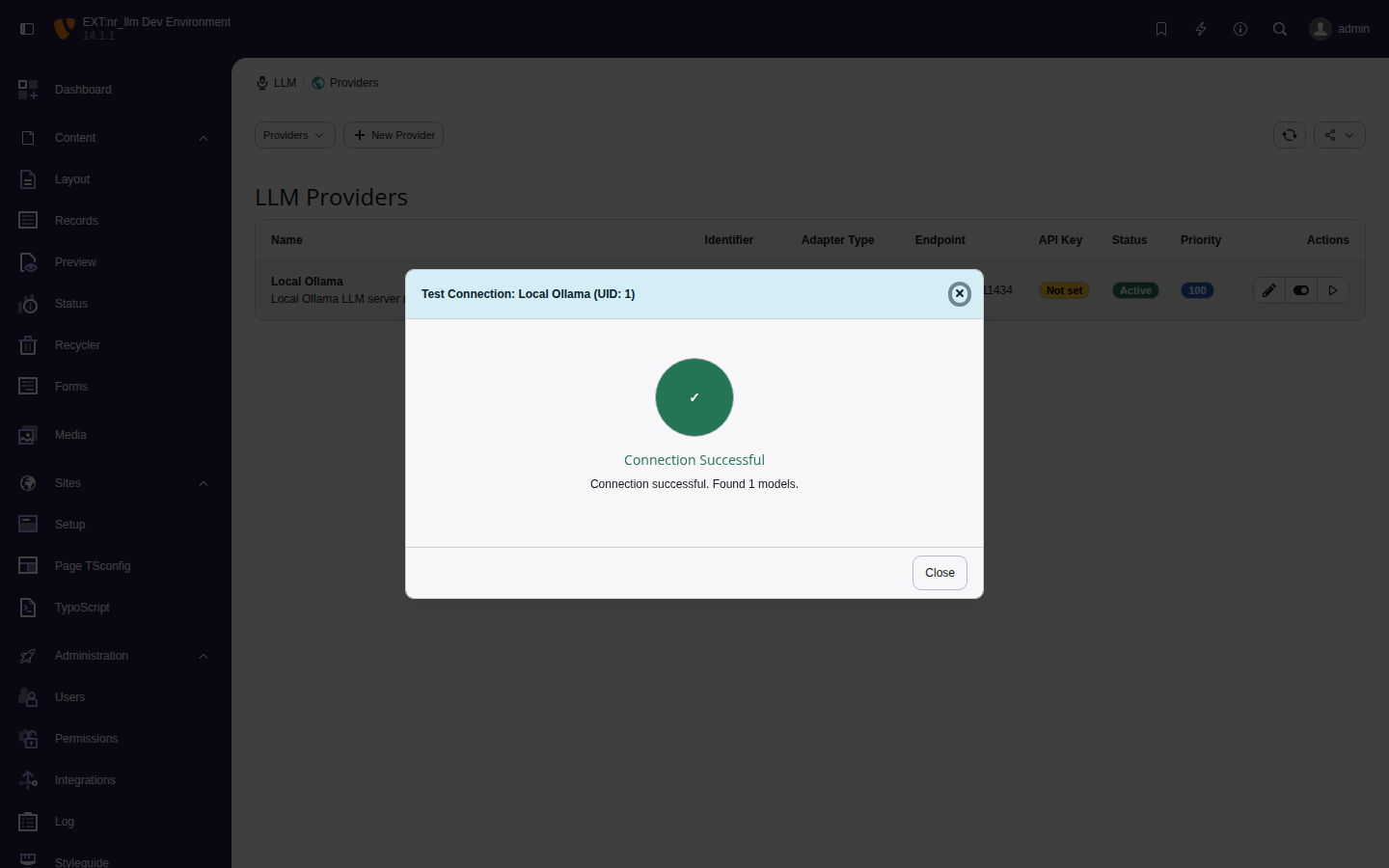
Testing a connection
After saving a provider, click
Test Connection to verify the setup.
The test makes an HTTP request to the provider API
and reports:
Connection status (success or failure).
Available models (if the provider supports
listing).
Error details on failure.
Successful connection test for the Local Ollama
provider.
Note
Self-hosted endpoints (such as Ollama) reached through a hostname
that resolves to a private or loopback address are subject to the
SSRF protection built into nr-vault's HTTP client. If a connection
test fails with a "disallowed IP range" error, add the endpoint
host to the TYPO3 HTTP allowlist:
The request-time allowlist is honored by nr-vault 0.6.1 and later.
Endpoints given as an IP literal (for example
http://127.0.0.1:11434) are not affected.
Editing and deleting providers
Click a provider row to edit its settings.
Use the Delete action to remove a
provider. Models linked to a deleted provider
become inactive.
Managing models
Models represent specific LLM models available
through a provider (e.g., gpt-5,
claude-sonnet-4-6, llama-3).
The model list with capability badges, context
length, and cost-per-token columns.
Adding a model manually
Navigate to Admin Tools > LLM >
Models.
Click Add Model.
Fill in the required fields:
Identifier
Unique slug (e.g., gpt-5,
claude-sonnet).
Name
Display name (e.g., GPT-5 (128K)).
Provider
Select the parent provider.
Model ID
The API model identifier as the provider
expects it (e.g., gpt-5.3-instant,
claude-sonnet-4-6).
Optionally set capabilities (chat,
completion, embeddings, vision,
streaming, tools), context length,
max output tokens, and pricing.
Click Save.
Fetching models from a provider
Instead of adding models manually, use the
Fetch Models action to query the
provider API and auto-populate the model list:
Ensure the provider is saved and the connection
test passes.
On the model list or model edit form, click
Fetch Models.
The extension queries the provider API and
creates model records with capabilities and
metadata pre-filled.
This is the recommended approach — it ensures model
IDs match the provider exactly and keeps your
catalogue current as providers release new models.
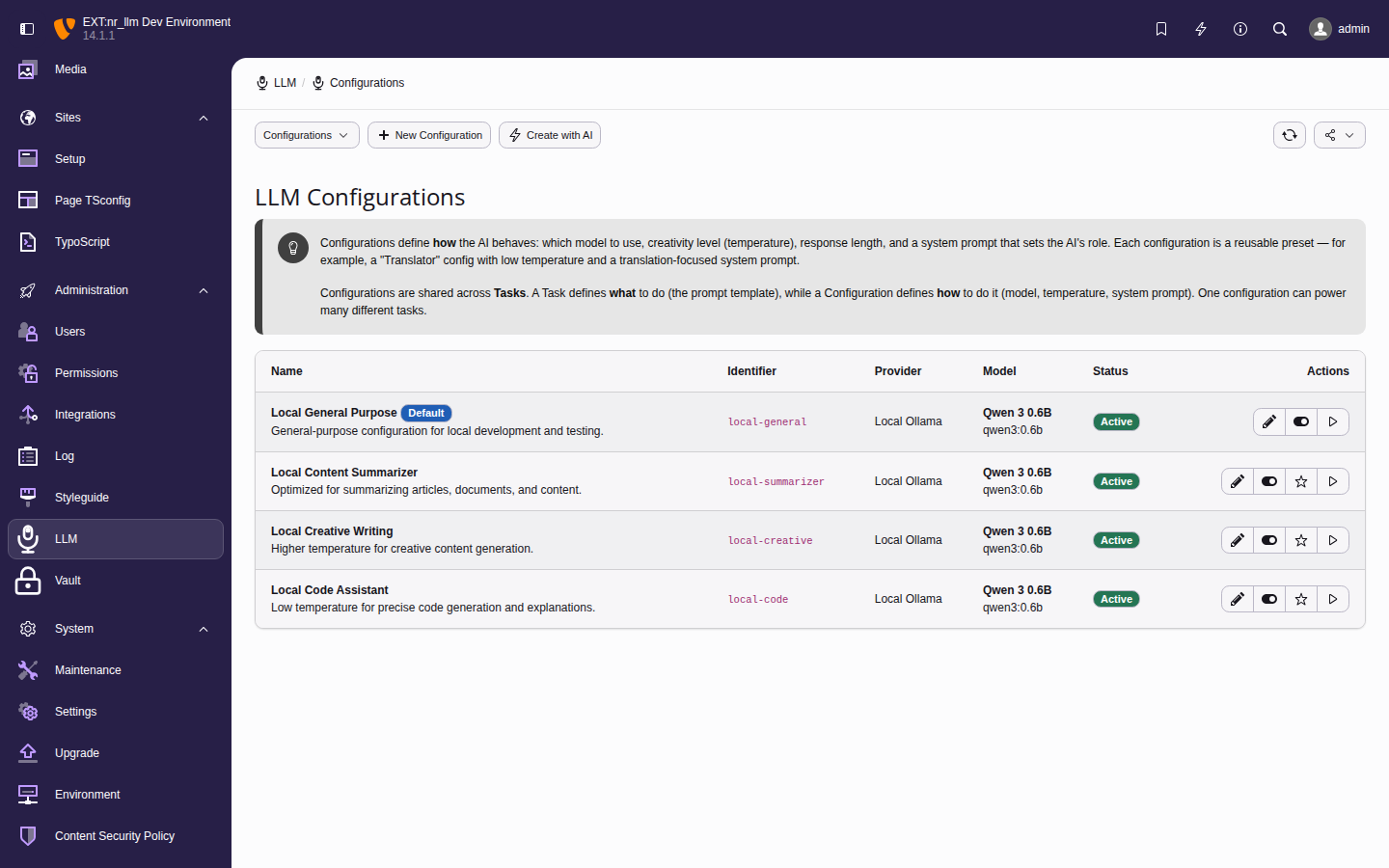
Managing configurations
Configurations define use-case-specific presets that
combine a model with a system prompt and generation
parameters. Extension developers reference
configurations by identifier in their code.
The configuration list showing each entry's
linked model, use-case type, and key parameters.
Adding a configuration manually
Navigate to Admin Tools > LLM >
Configurations.
Click Add Configuration.
Fill in the required fields:
Identifier
Unique slug for programmatic access
(e.g., blog-summarizer).
Name
Display name (e.g., Blog Post Summarizer).
Model
Select the model to use.
System Prompt
The system message that sets the AI's behavior
and context.
Optionally adjust temperature (0.0-2.0), top_p,
frequency/presence penalty, max tokens, and
use-case type (chat, completion,
embedding, translation).
Click Save.
Tip
Use the Configuration wizard to generate all
fields from a plain-language description of your
use case.
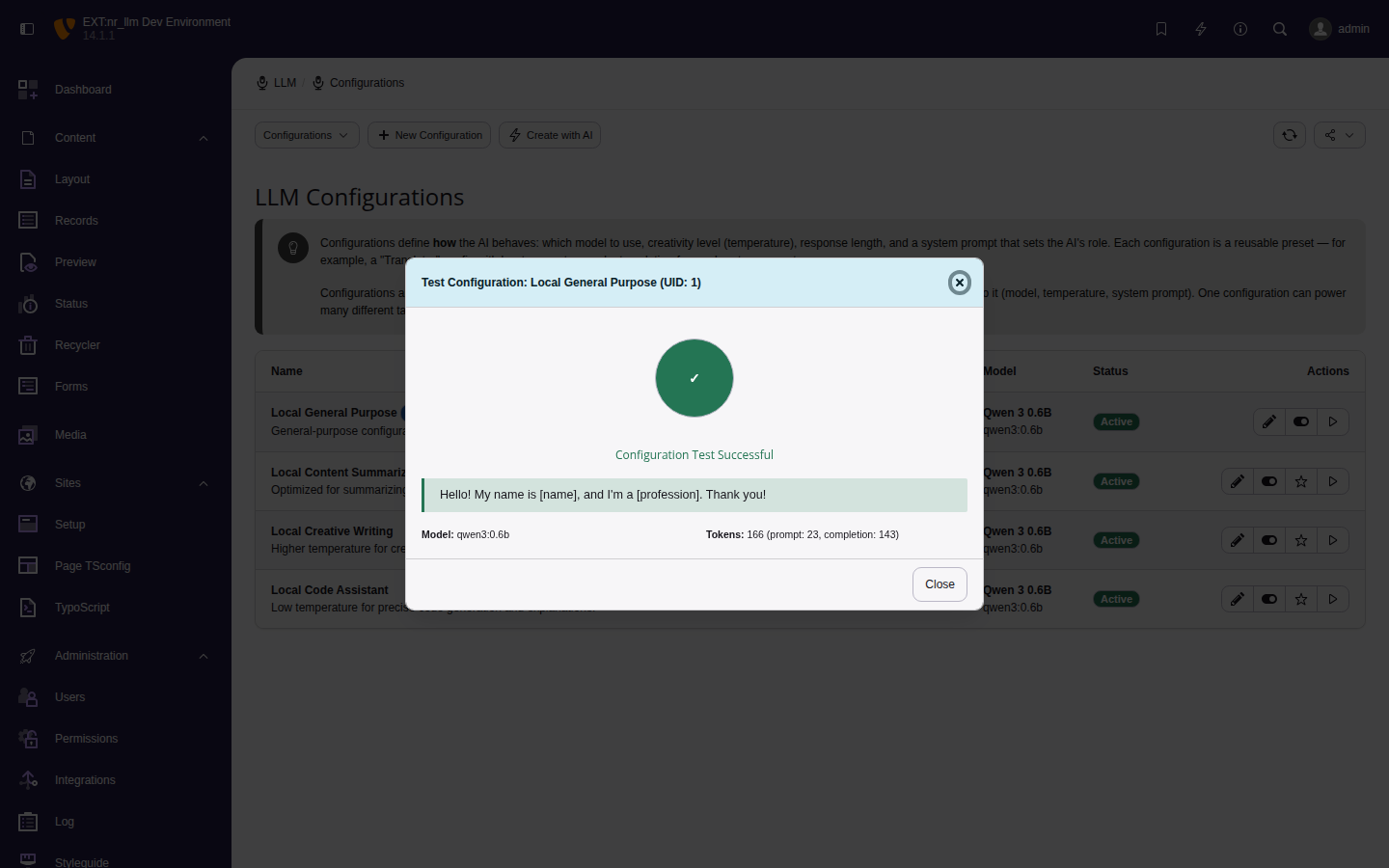
Testing a configuration
Click Test Configuration on any row.
The test sends a short prompt to the model and shows
the response, model ID, and token usage.
Successful configuration test with token count.
Editing configurations
Click a configuration row to edit. Changes take
effect immediately for any extension code that
references this configuration's identifier — no
code deployment needed.
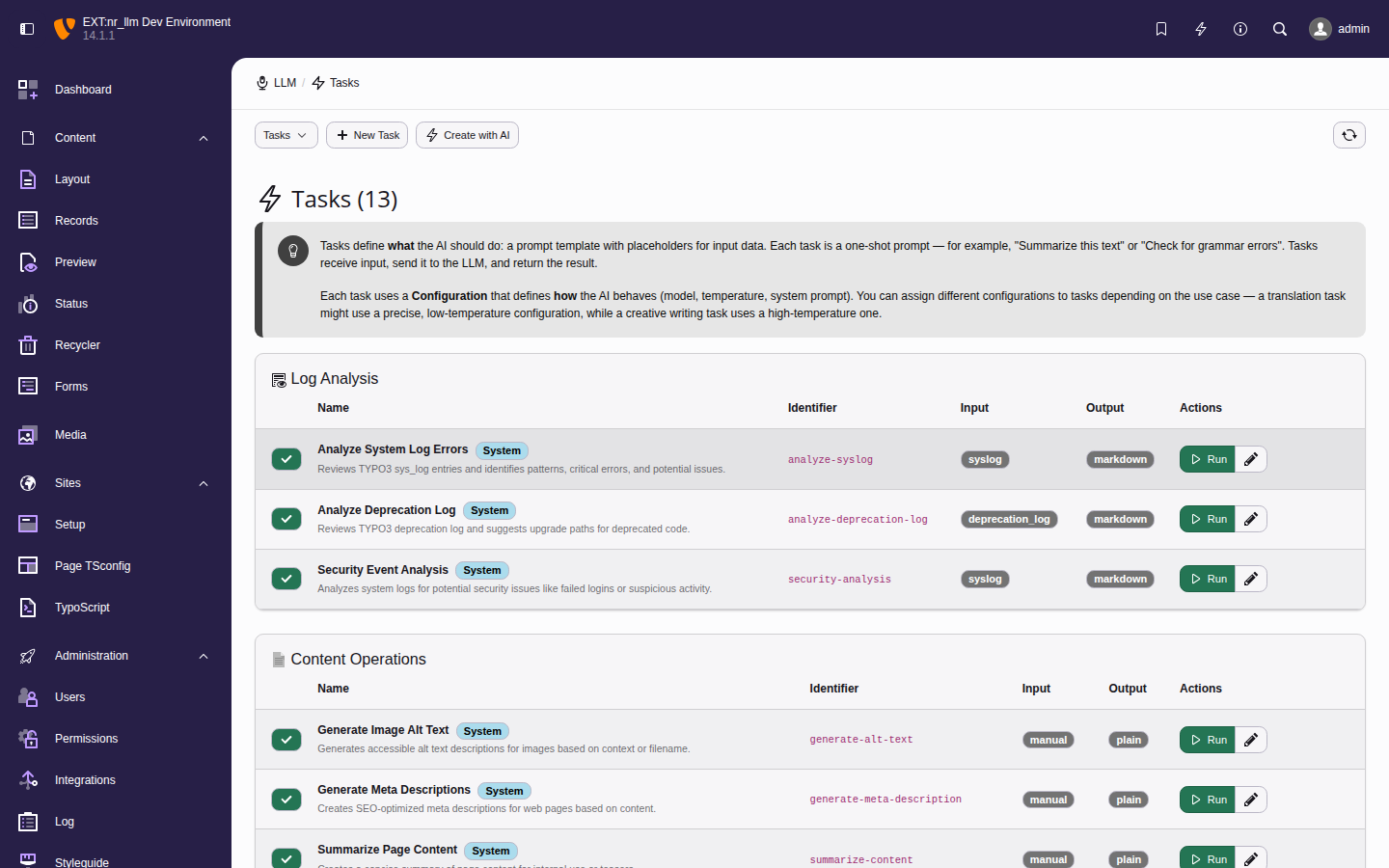
Managing tasks
Tasks are one-shot prompt templates that combine a
configuration with a specific user prompt. They
provide reusable AI operations that editors or
extensions can execute with a single call.
The task list with each task's assigned
configuration and action buttons.
Adding a task manually
Navigate to Admin Tools > LLM >
Tasks.
Click Add Task.
Fill in the required fields:
Name
Display name (e.g., Summarize Article).
Configuration
Select the LLM configuration to use.
User Prompt
The prompt template. Use {placeholders}
for dynamic values.
Add a description so other admins understand
what the task does.
Click Save.
Executing a task
Click Run on any task to open the
execution form. It shows the configuration, model,
parameters, input field, and prompt template.
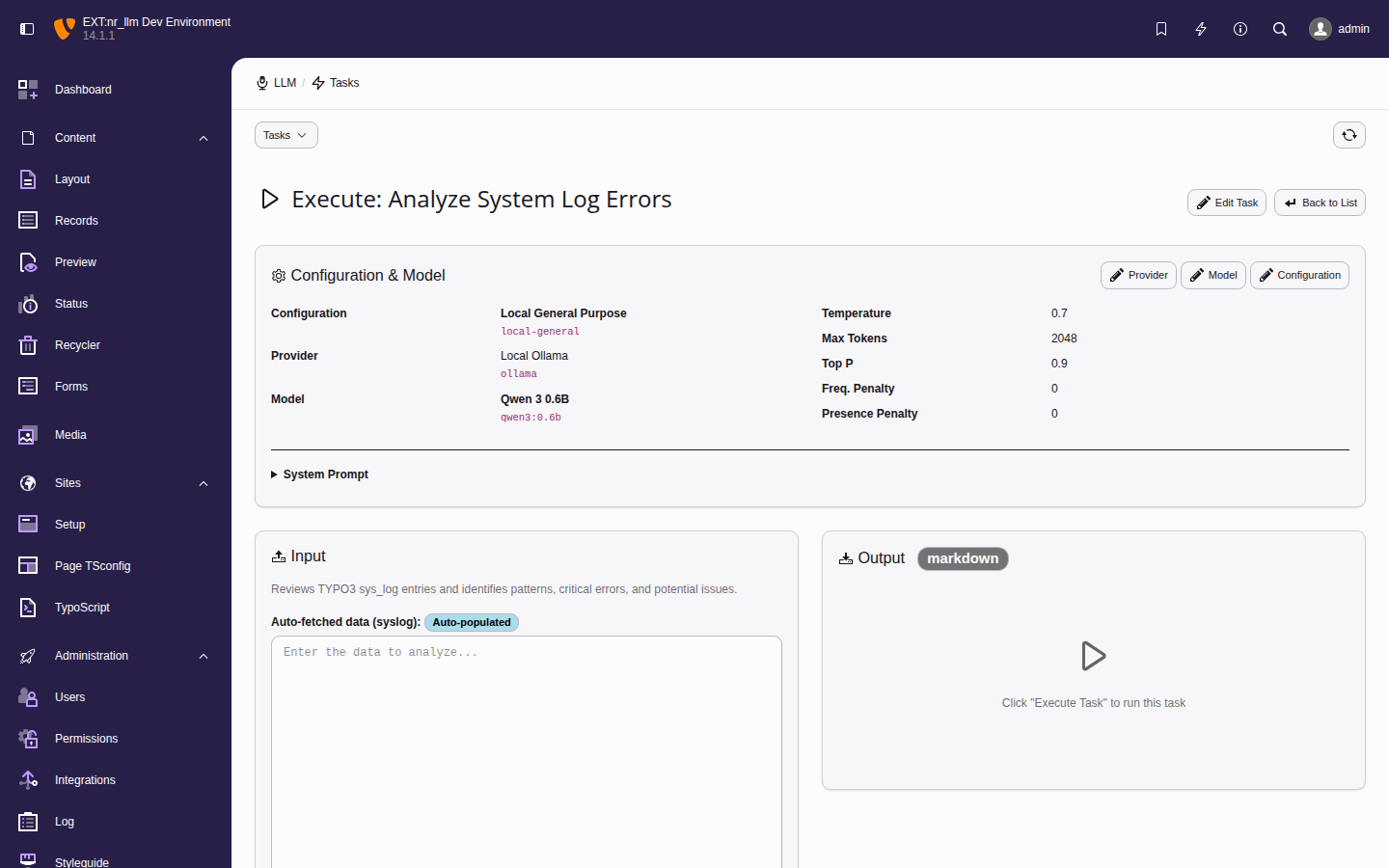
The task execution form for "Analyze System Log
Errors" with the Ollama provider and Qwen 3 model.
Example tasks:
Summarize content — condense long articles.
Generate meta descriptions — SEO optimization.
Translate text — one-click translation.
Extract keywords — pull key terms from content.
Tip
Use the Task wizard to generate
a complete task (including a new configuration)
from a plain-language description.
Managing prompt snippets
Prompt snippets are small named prompt fragments —
personas, tones of voice, target audiences, image
styles, layouts — that editors manage centrally.
Consuming extensions (for example nr_repurpose)
query snippets by tag and compose them into their
prompts.
Snippets are deliberately not prompt templates:
a prompt template is a complete,
versioned prompt with model parameters, while a
snippet is a reusable building block without any
model binding.
Comma-separated tags consuming extensions
search for (see below).
Snippet text
The prompt fragment itself.
Metadata (JSON)
Optional JSON object with extra settings.
Click Save.
Tag convention
Tags are free-form, comma-separated strings. There
is no fixed vocabulary — consuming extensions agree
on tags with the editors. Matching is exact per tag
and case-insensitive: the tag style does not
match a snippet tagged lifestyle.
Established tags so far:
Tag
Used for
audience
Target audience descriptions
tone_of_voice
Tone-of-voice instructions
persona
Writing/speaking personas
layout
Layout instructions (e.g. for slides)
style
Image / visual style descriptions
Persona snippets may carry a voice hint in their
metadata so speech features can pick a matching
text-to-speech voice:
Metadata of a persona snippet
{"voice": "nova"}
Copied!
Using snippets from an extension
Query snippets by tag through the public
PromptSnippetRepository and compose the
selected fragments with the
PromptSnippetComposer:
composeSections() renders each non-null
snippet as a LABEL: block followed by the
snippet text, joined by blank lines. Null entries
and empty snippets are skipped.
Skills are GitHub-hosted SKILL.md files — a YAML front-matter block
with a name and description plus a markdown body — that nr-llm can
ingest, review, and (from Plan 1b) inject into prompts. You add a skill
source that points at GitHub, sync it, and then enable the individual
skills you want.
Skill management is admin-only. It lives in
Admin Tools > LLM > Skills and is not delegated to other
backend groups: a skill body becomes prompt context, so the two skill
tables are treated as a privilege-escalation surface.
Note
Ingest — adding sources, syncing and reviewing — is described by
ADR-035. Attaching enabled skills to tasks and
configurations and injecting them into text-generation prompts is
described by ADR-036 and the
Attaching skills section below.
Source types
A source has one of three types:
single_file
One SKILL.md at a fixed path in a repository. A single, explicit
admin act — its skill may default to enabled.
repo
A whole repository. Every SKILL.md under the repo root,
skills/<name>/, .claude/skills/<name>/ or
<plugin>/skills/<name>/ is discovered. Discovered skills arrive
disabled for review.
marketplace
An Anthropic marketplace.json index that lists plugins pointing at
further repositories. Each entry is expanded with the repo flow.
All discovered skills arrive disabled.
Adding a source
Navigate to Admin Tools > LLM > Skills.
Click New Skill Source.
Fill in the fields:
Title
Display name for the source list.
Type
single_file, repo or marketplace (see above).
URL
The GitHub URL the type expects (the SKILL.md URL, the
repository URL, or the marketplace.json URL).
Ref
A branch or tag (for example main or v1.2.0). It is
resolved once to an immutable commit SHA at sync time; all
bodies are then fetched by that SHA, never by the moving branch.
Click Save.
The pinned_sha, sync_status, sync_error and last_synced
fields are managed by the sync run and shown read-only.
GitHub token and rate limits
Unauthenticated GitHub API access is limited to 60 requests per hour,
which is quickly exhausted by a repo or marketplace sync. Add a
personal access token (a read-only, public-repo token is enough) to raise
the limit and to read private repositories.
The token is set through the Set token action on a source,
not typed into a FormEngine field. It is stored as an nr-vault UUID
(envelope-encrypted), mirroring provider API-key storage — never as
plaintext in TCA, YAML or the database.
When a sync hits the rate limit (HTTP 403 with no remaining quota), the
source is set to sync_status = error carrying the reset time; state
is not partially corrupted. Add a token and re-sync.
Host-allowlist prerequisite
nr-llm enforces an app-level GitHub allowlist on every skill request:
the scheme must be https and the host must be one of github.com,
raw.githubusercontent.com, api.github.com or
codeload.github.com. This is separate from, and in
addition to, the nr-vault SSRF guard.
On hardened instances that restrict outbound HTTP through the global
HTTP/allowed_hosts SSRF setting, those four GitHub hosts must be on
that list, otherwise every sync fails closed. This is a deliberate
prerequisite — nr-llm never silently bypasses the SSRF guard.
Syncing and the review flow
The Skills module — the Sources table (type, sync status,
last synced, per-source actions) above the discovered Skills
with their partial / full support badge and enabled state.
On a source, click Sync. The source moves through
never_synced → syncing → ok / partial / error.
The syncing state also acts as a lock: a second concurrent sync on
the same source is refused.
partial means the per-sync file-count or wall-time bound was
reached (large marketplaces); the skills fetched so far are stored.
Discovered skills from repo and marketplace sources are
created disabled by default. Review each one, then toggle it on
with Enable.
Re-sync never silently changes an enabled skill. If a re-sync
recomputes a different body_checksum for an enabled skill, nr-llm
auto-disables it and surfaces a diff (Review changes)
so you re-confirm before it is used again. Accepting the diff re-pins
the SHA atomically.
A skill that disappeared upstream is marked orphaned and disabled,
never silently dropped, so attachments (Plan 1b) do not vanish.
Deleting a source cascade-deletes its skills.
The partial support badge
Each skill carries a support badge:
full
The skill is plain front-matter and prose.
partial
The body or front-matter references scripts, references/,
assets/ or an allowed-tools declaration.
Warning
partial is not a "safer content" badge. It only signals that
the referenced scripts and assets are not executed by nr-llm
(which is true for every skill in this release). The prose itself is
fully untrusted regardless of the badge. Asset references are stripped
from injected prose purely to avoid dangling instructions, not as a
security control.
See ADR-035 for the full design and security rationale.
Attaching skills and injecting them into prompts
Enabled, non-orphaned skills can be attached to a Task and/or an
LLM configuration via the Skills field on those records
(only enabled skills are offered). At execution time, for text-generation
operations only — completion, translation and task execution; never
embeddings, vision or speech — nr-llm composes the attached skills into a
delimited block and prepends it to the user prompt. The configuration
system_prompt is never modified.
Note
Injection is eager and complete, not on demand. The whole skill
body — the entire SKILL.md prose after the front-matter, not just
the name/description — is written into the prompt before the model
runs. Unlike a tool, a skill is not
something the model calls or fetches when it decides it needs it: there is no
runtime round-trip that loads a skill's body, and none that loads its
references/ / scripts/ / assets/ (those lines are stripped from
partial skills, and the files are never executed). An attached skill
therefore always costs its full body in tokens on every run (subject to the
budget below).
Planned direction (not in this release): a progressive-disclosure mode
that injects only the description and lets the model pull the full body
or a referenced file on demand — the same shape as the tool runtime.
Executing a skill's bundled scripts or assets is a separate, harder step and
is not on the near-term roadmap.
Composition rules:
Precedence. Configuration skills are the baseline, task skills are
additive; the set is the union deduped by source + identifier (the
configuration wins on a duplicate). The configuration block renders
first.
Budget. The block is bounded by a conservative character budget;
when it is exceeded, task-additive skills are dropped before
configuration-baseline skills and each drop is logged.
Integrity. Each skill's body checksum is re-verified at injection
time; a mismatch (tampering or a stale row) drops that skill — it is
never injected.
Untrusted output. Skill prose is third-party text; output produced
under its influence is treated as untrusted and escaped/sanitized where
it is stored or rendered. Message role is defense-in-depth, not a trust
boundary.
Tools are small, admin-curated PHP functions the model may call
mid-generation. Where a normal completion answers in one shot, a tool run
is a bounded agent loop: the model may ask to call a tool, nr-llm executes
it, feeds the result back, and re-asks — until the model answers or an
iteration cap is reached. The v1 consumer is the interactive
Tool Playground.
The Tool Playground — the only
tool-running surface in this release — is admin-only. The runtime itself
applies a two-tier gate: each tool declares requiresAdmin(), and
ToolLoopService drops admin-only tools when the acting backend user is
not an administrator. Most built-in tools require admin because a tool runs
with full TYPO3 privileges, has no per-record authorization, and its return
value egresses both to the configured LLM provider and to the rendered
backend output; only a few read-only, scope-limited tools are offered to
non-admin users.
Note
The runtime design and its security and cost rationale are recorded in
ADR-038. Skill ingest and injection — which can steer
which tools a run may use and what arguments the model chooses — are
ADR-035 / ADR-036 and the
Managing skills guide.
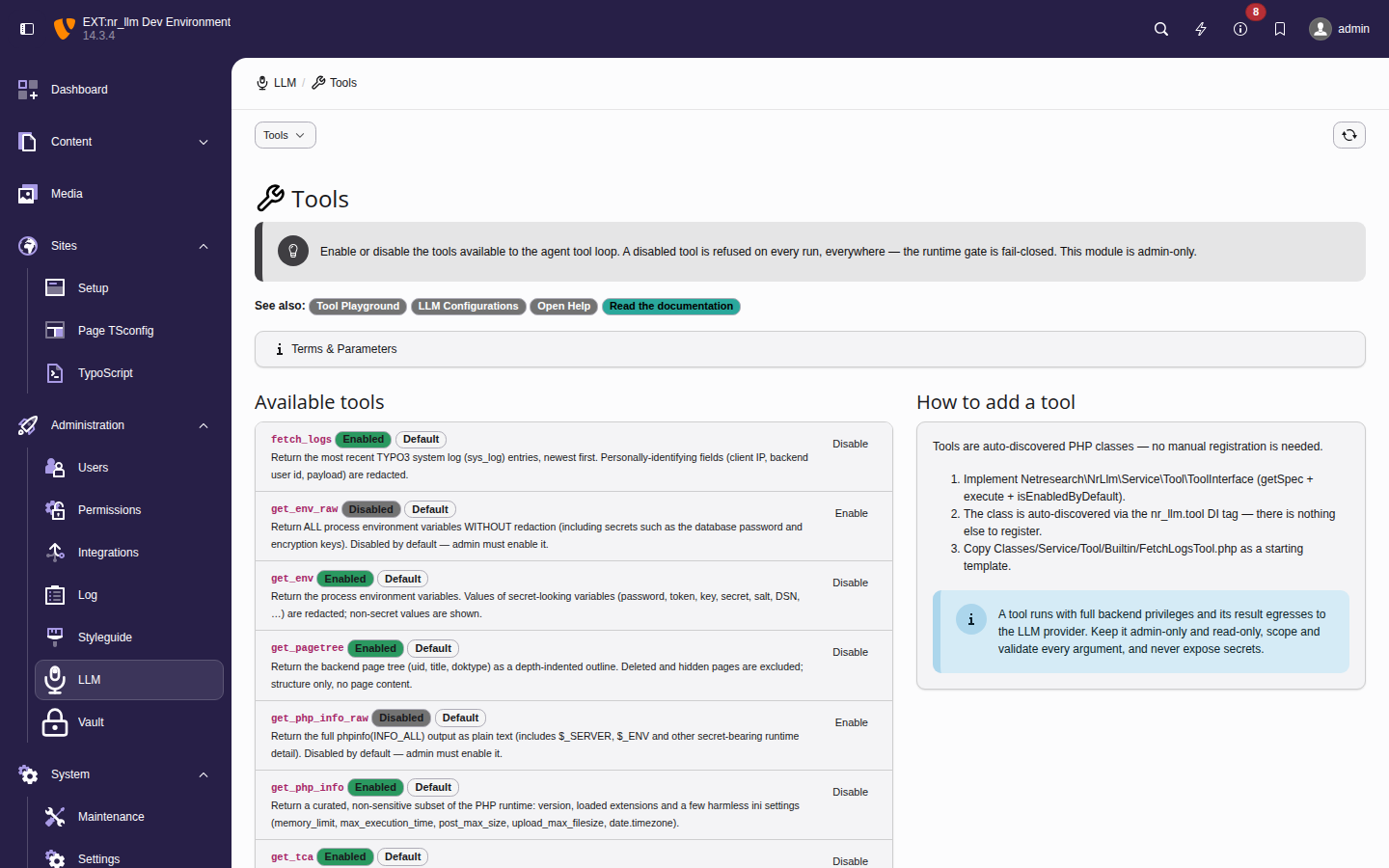
The built-in tools
nr-llm ships eleven read-only introspection tools. Each is a reference
implementation of the security contract: model-chosen arguments are
validated and scoped, volumes are capped, and secret-bearing output is either
redacted or gated behind a separate _raw variant. Eight ship enabled;
the three unredacted _raw variants (get_env_raw, get_php_info_raw
and list_be_users_raw) ship disabled and must be enabled deliberately.
Most require admin; only get_pagetree, get_tca and
read_fal_asset_meta are offered to non-admin backend users.
The two tools below are the fullest illustrations of the contract:
fetch_logs
Returns the most recent sys_log entries, newest first, with an
optional PSR level filter and a limit (default 20, hard-capped
at 50). Personally-identifying fields — the client IP, the backend user
id and the serialized payload — are redacted by omission, because the
result egresses to the external provider.
read_fal_asset_meta
Returns read-only metadata (file name, MIME type, size, title, alternative
text) for a single managed file (sys_file) by its uid. The uid is
model-chosen and therefore injection-steerable, so the lookup is
storage-scoped (default: the default storage). A uid in a non-permitted
storage returns the same neutral "not found or not permitted" string as a
missing uid — the model cannot enumerate arbitrary files.
The remaining tools follow the same pattern:
get_env / get_env_raw
Process environment variables. get_env redacts secret-looking values
(password, token, key, secret, salt, DSN, …); get_env_raw returns them
unredacted (database password, encryption key) and ships disabled.
get_php_info / get_php_info_raw
PHP runtime configuration. get_php_info is redacted; get_php_info_raw
returns the full, secret-bearing phpinfo detail and ships disabled.
get_pagetree
The backend page tree (uid, title, doktype) as a depth-indented outline;
deleted and hidden pages are excluded — structure only, no content.
get_tca
The TYPO3 TCA schema: with no argument it lists the configured table names;
with a table argument it returns that table's field definitions.
list_be_groups
The backend user groups (uid, title).
list_be_users / list_be_users_raw
Backend users. list_be_users omits credentials (password hashes and MFA
secrets are never included); list_be_users_raw returns the full
non-credential profile columns and ships disabled.
Registering a tool
A tool is a PHP class that implements
Netresearch\NrLlm\Service\Tool\ToolInterface:
getSpec(): ToolSpec
Returns the declaration the model receives — a name, a description, and a
JSON-Schema parameters block. Build it with
ToolSpec::function($name, $description, $parameters).
execute(array $arguments): string
Runs the tool with the model-provided arguments and returns a plain
string that is fed back into the conversation as a tool turn.
The interface carries #[AutoconfigureTag('nr_llm.tool')], so a class is
auto-registered simply by implementing it — no central registration file
to edit. ToolRegistry collects every tagged tool through a DI iterator
and indexes it by spec name; two tools with the samename is a
developer error and fails fast at container build.
When you write a tool, honour the security contract: treat $arguments as
attacker-influenced (the model is steerable by injected skill prose),
validate and scope every input (cap volumes, scope identifier lookups),
and never return secrets — the result leaves the instance.
Managing tools
The Admin Tools > LLM > Tools module lists every registered tool
with its global enable state and lets an admin toggle it. A disabled tool
is refused on every run, everywhere — the runtime gate is fail-closed, so a
disabled tool can never be offered to the model regardless of a skill's
allowed-tools or the per-run selection in the playground. Some built-in
tools (for example get_env_raw and get_php_info_raw) ship disabled
by default because they return unredacted, secret-bearing output; enable
them only deliberately.
The Tools module — each registered tool with its global enable state and a
toggle. The _raw variants show as Disabled, the redacted
tools as Enabled; the Default badge marks a tool
sitting at its shipped state.
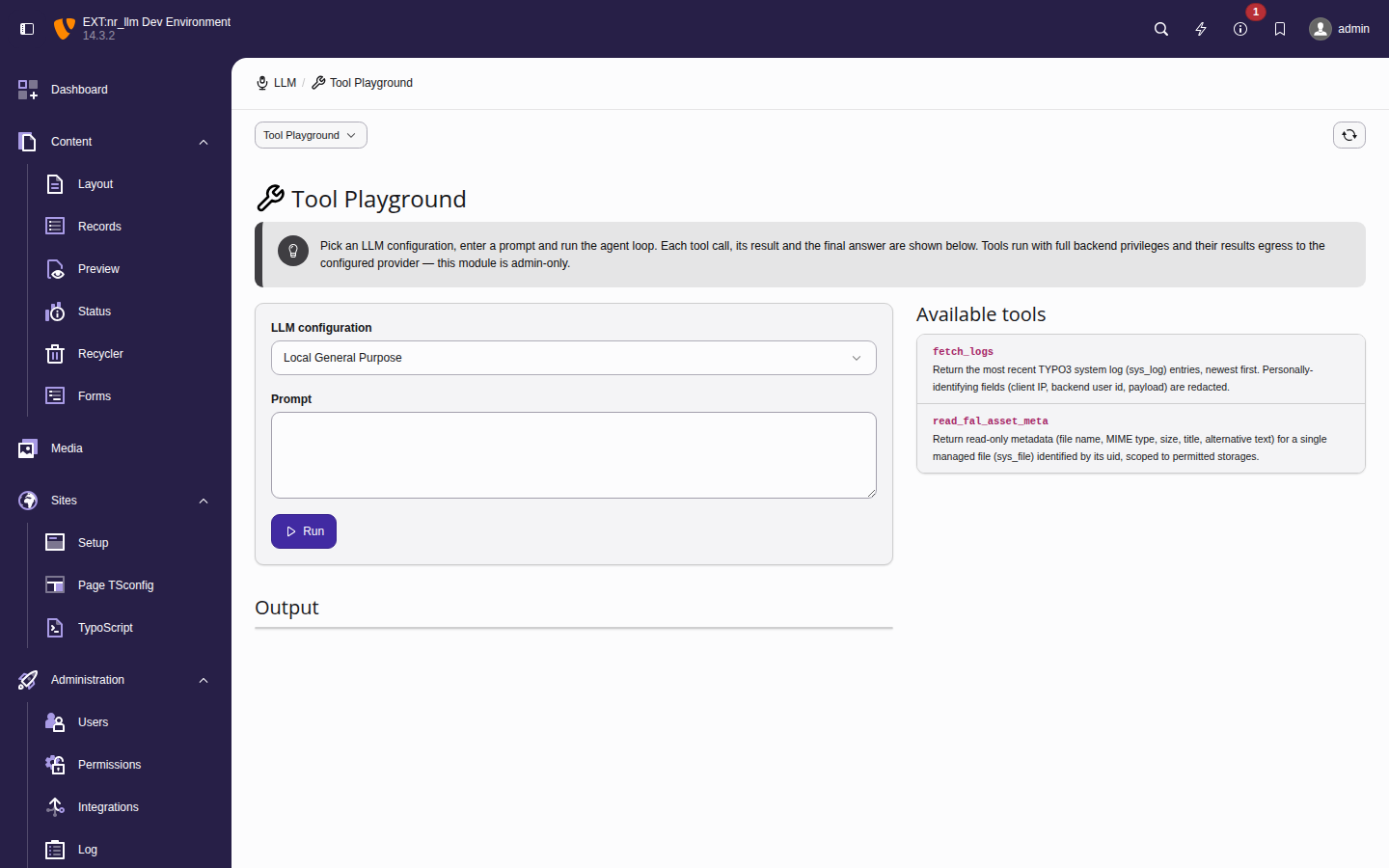
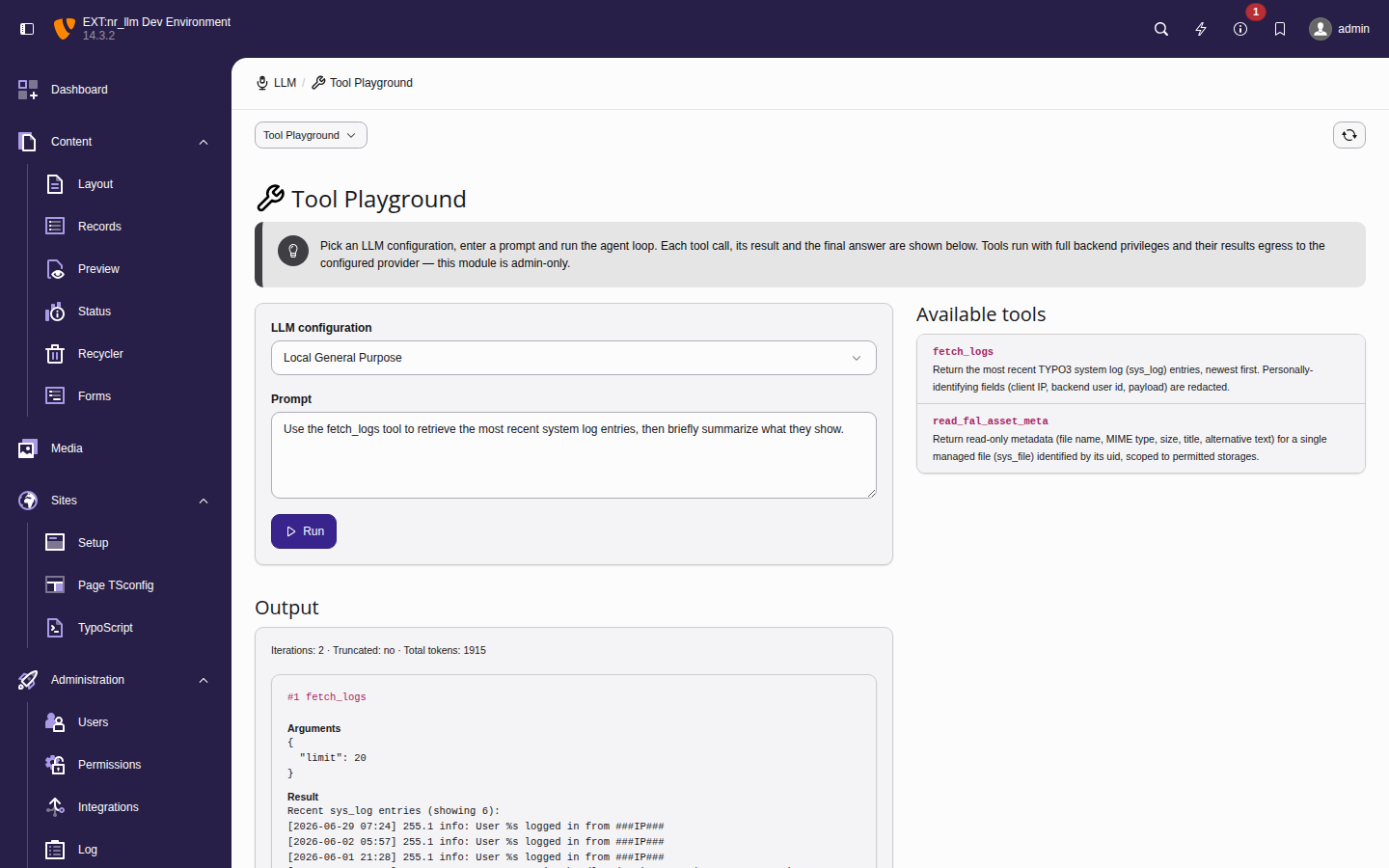
Using the Tool Playground
The playground lives in Admin Tools > LLM > Playground and is
admin-only. It is a sibling of the Tools management module: the playground runs the
loop, while the Tools module governs which tools exist and are enabled.
The playground shell — the configuration picker, prompt box and the
Tools available to this run panel, which lists every
registered tool with the default-enabled ones pre-checked and the
disabled _raw variants unchecked.
Pick an LLM configuration from the dropdown. Its vault-stored API key,
model, temperature and system prompt are what the loop actually runs on —
the playground never falls back to a default model.
Type a prompt and click Run.
Read the trace. Each tool the model called is shown in order with its
name, the arguments the model chose, and the tool's result (errors are
badged). The model's final answer follows the trace.
A completed run — a two-iteration loop in which the model called
fetch_logs (arguments {"limit": 3}); the redacted sys_log
result is fed back and the model's final answer closes the trace.
The Tools available to this run list lets you narrow a single run
to a subset of the globally-enabled tools (the full list and the global
enable/disable controls live in the Tools module). Every displayed string — tool
arguments, tool results (which may include sys_log content), and the
final answer — is rendered escaped; HTML is only ever shown inside a
sandboxed preview, never injected into the page.
Each run is bounded by the iteration cap (default 5) and, when the
configuration's backend user has a budget, by the per-iteration budget
pre-flight. If the cap is hit with tools still pending, a final tool-free
completion synthesises a closing answer and the run is marked truncated.
The aggregated token usage is reported; the monetary cost is recorded in
the usage table by the middleware pipeline.
Ollama model-capability dependency
Tool calling depends on the model, not just the provider. For Ollama,
only function-calling-capable models — for example llama3.1,
mistral, qwen2.5 — return tool calls. A model without function-calling
support simply answers the prompt directly and never calls a tool; the
loop ends gracefully on the first plain answer. If a configured Ollama model
never seems to use the available tools, verify it is one of the
function-calling models for your Ollama version.
Gating tools with allowed-tools in a skill
A skill's SKILL.md front-matter may carry an allowed-tools key that
gates which tools the skills attached to a configuration (or task) grant for a
run. The resolution is fail-closed on declaration, computed over the
configuration's effective skills (enabled, non-orphaned — exactly the set
that is injected into the prompt):
Absent (no skill declares allowed-tools) — no opinion; all
registered tools are offered.
Declared list — the union of the declared lists across the effective
skills; only those tools are offered (intersected with what is actually
registered, so an unknown name is dropped).
Declared empty (allowed-tools: []) — declares zero tools; if no
other effective skill widens the set, the run gets no tools and is a single
plain completion.
A disabled or orphaned skill never grants tools. The allow-list is enforced
both when the tools are offered to the model and again when a tool call is
executed, so a prompt injection cannot reach a tool the skills did not grant.
See ADR-038 for the runtime design and security rationale.
AI-powered wizards
The extension includes AI-powered wizards that use
your existing LLM providers to generate
configurations and tasks automatically. This reduces
manual setup to a minimum.
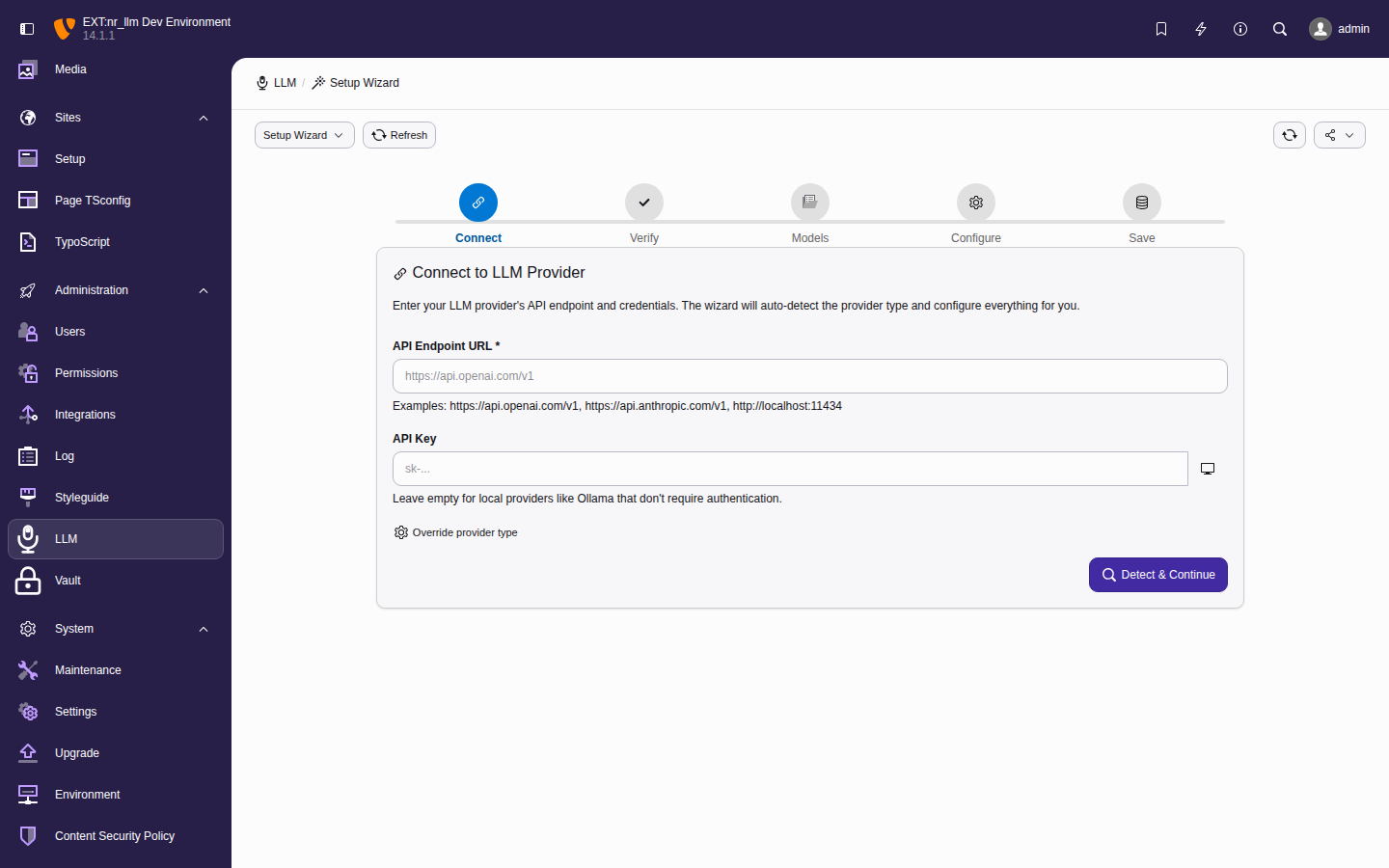
Setup wizard
The setup wizard guides first-time configuration in
five steps:
Connect — enter your provider endpoint and
API key.
Verify — test the connection.
Models — fetch available models from the
provider API.
Configure — create an initial configuration
with system prompt and parameters.
Save — run a test prompt to confirm
everything works.
The setup wizard walks through provider creation,
connection testing, model fetching, configuration,
and a test prompt in five steps.
Access it from the Dashboard when no
providers are configured, or via the setup wizard
link at any time.
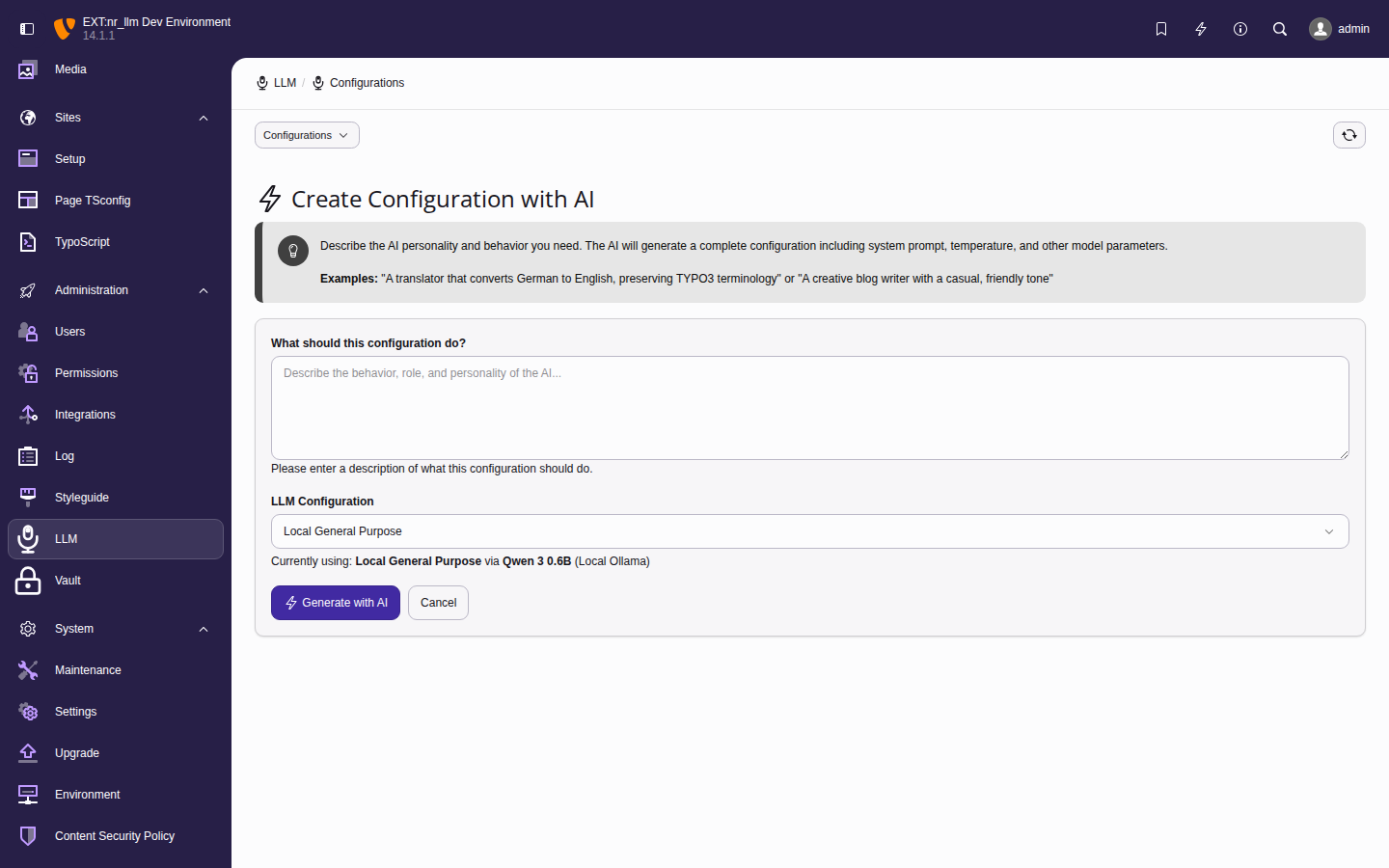
Configuration wizard
The configuration wizard generates a complete LLM
configuration using AI. Instead of filling in each
field manually, describe your use case in plain
language and the wizard generates everything.
Navigate to Admin Tools > LLM >
Configurations.
Click Create with AI.
Describe your use case (e.g., "summarize blog
posts in three sentences").
The wizard generates: identifier, name, system
prompt, temperature, and all other parameters.
Review and click Save.
The configuration wizard generates all fields
from a natural-language description.
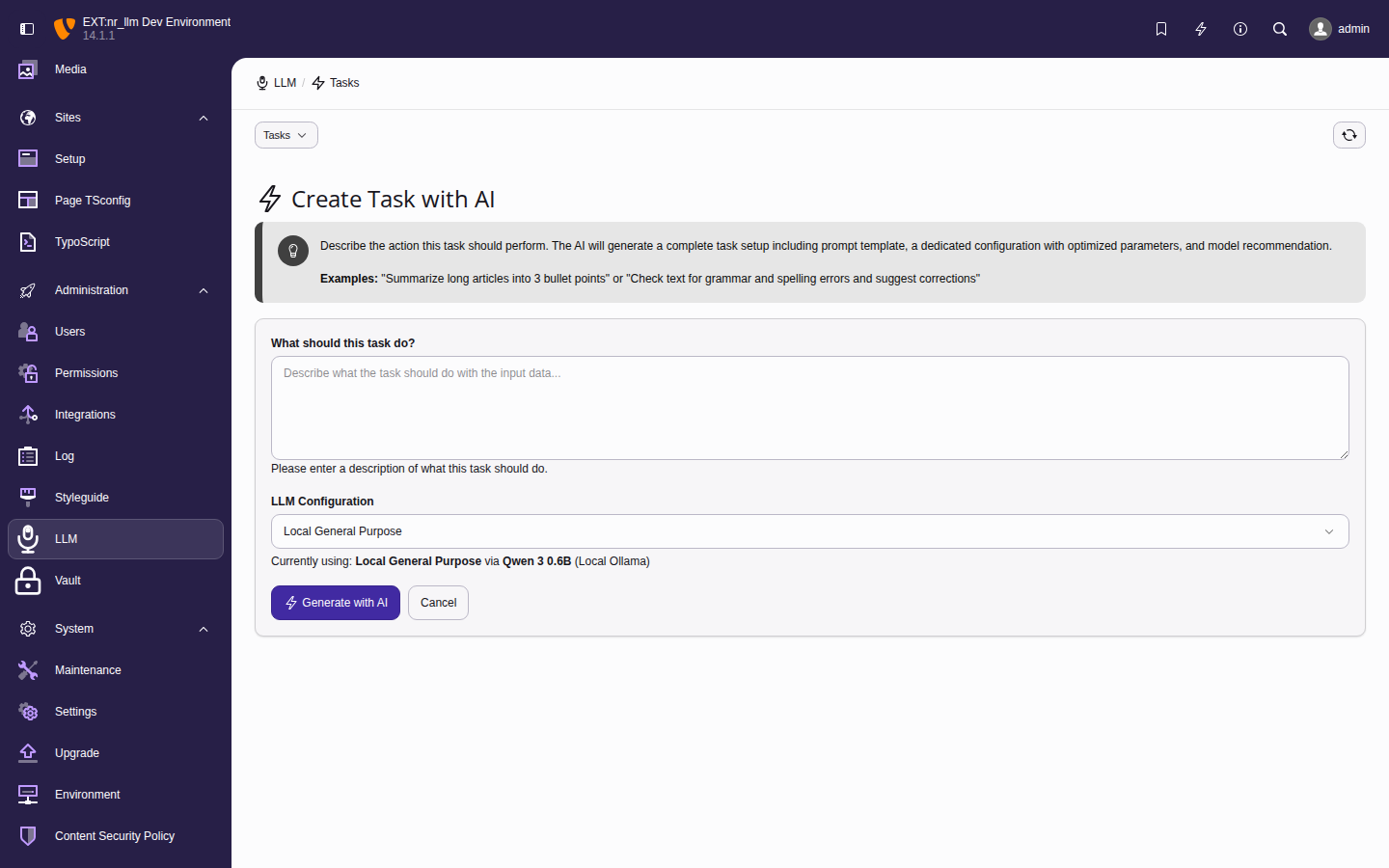
Task wizard
The task wizard creates a complete task setup — a
task and a dedicated configuration — in one
step.
Navigate to Admin Tools > LLM >
Tasks.
Click Create with AI.
Describe the task (e.g., "extract the five most
important keywords from an article").
The wizard generates: a task with prompt template,
a configuration with system prompt and parameters,
and a model recommendation.
Review and click Save.
The task wizard generates a complete task and
configuration from a description.
Model discovery
On the model edit form, use the
Fetch Models button to query the
provider API. This auto-populates available models
with their capabilities, context length, and
pricing metadata.
Recommended workflow
For a fresh installation:
Run the Setup wizard from the dashboard
to create your first provider, fetch models,
and test a configuration.
Use the Configuration wizard to create
additional use-case configurations (one per
use case in your extensions).
Use the Task wizard to create reusable
prompt templates for editors.
Share configuration identifiers with your
extension developers — they reference them
in code via
$configRepository->findByIdentifier('...').
For ongoing maintenance:
Add providers when you need additional
AI services or separate prod/dev keys.
Fetch models periodically to pick up new
models from providers.
Edit configurations to tune prompts and
parameters — changes take effect immediately
without code deployment.
Per-user AI budgets
The tx_nrllm_user_budget table caps per-backend-user AI spend
independently of the per-configuration daily limits on
tx_nrllm_configuration. A user request must clear BOTH layers:
any limit on the preset they chose AND any limit on their personal
budget record.
What a budget caps
Each row in tx_nrllm_user_budget binds to exactly one
be_user and defines six independent ceilings. 0 on any axis
means "unlimited on this axis".
Field
Unit
Reset cadence
Max Requests/Day
count
Every day at 00:00 server-local time.
Max Tokens/Day
count
Every day at 00:00 server-local time.
Max Cost/Day ($)
USD
Every day at 00:00 server-local time.
Max Requests/Month
count
First of the month, 00:00 server-local time.
Max Tokens/Month
count
First of the month, 00:00 server-local time.
Max Cost/Month ($)
USD
First of the month, 00:00 server-local time.
Usage is aggregated on demand from tx_nrllm_service_usage — the
same table the UsageTracker already writes to per request — so there
is no second write per request and no way for a separate counter to
drift away from the source of truth.
Creating a budget
Budget records have rootLevel = -1, so admins can create them at
the TYPO3 root (pid = 0) or on any regular page. Keeping them at
the root is the convention because budgets are site-wide admin
concerns, not page-scoped content; the recipe below follows that
convention.
Open Web > List in the root (page UID 0) — or on the
page where you keep other cross-site configuration records.
Click Create new record.
Choose LLM User Budget.
Pick the backend user, set the ceilings, toggle
Enforce this budget on.
Save.
Note
Only one budget row per backend user. The be_user column
is unique. Re-editing the existing row is the correct way to
tighten or relax limits.
How the check runs
Before dispatching a request the consuming extension calls
NetresearchNrLlmServiceBudgetService::check(). The service:
Returns allowed when the user has no budget record, when
Enforce this budget is off, or when every ceiling
is 0.
Aggregates today's usage and this month's usage in a single
database roundtrip.
Evaluates the daily window first; the monthly window only if the
daily window passes.
Adds +1 request and +plannedCost to the usage figures
before comparing, so a user at exactly the limit is still
allowed one more call.
The returned BudgetCheckResult names which bucket was tripped
(exceededLimit as a stable machine key, plus a human-friendly
reason string suitable for log output or caller-side wrapping).
Important
The check is best-effort, not a transactionally-safe gate.
Two concurrent requests for the same user can both pass
check() before either updates
tx_nrllm_service_usage, temporarily allowing a one-request
overshoot. Full serialisation would hot-path every AI request.
If strict enforcement matters, layer a per-user lock on top.
Budgets vs. configuration limits
Both layers persist but cap different things:
Axis
Configuration daily limits
Per-user budgets
Bound to
a preset (tx_nrllm_configuration)
a backend user (tx_nrllm_user_budget)
Question answered
"Can ANY editor keep using this preset today?"
"Can THIS editor keep spending this month?"
Windows
daily
daily AND monthly
Dimensions
requests, tokens, cost
requests, tokens, cost
Both must pass
yes
yes
See ADR-025: Per-User AI Budgets for the full design rationale, including the
alternatives (counter table, group-level budgets, auto-throttling)
we considered and why they were rejected.
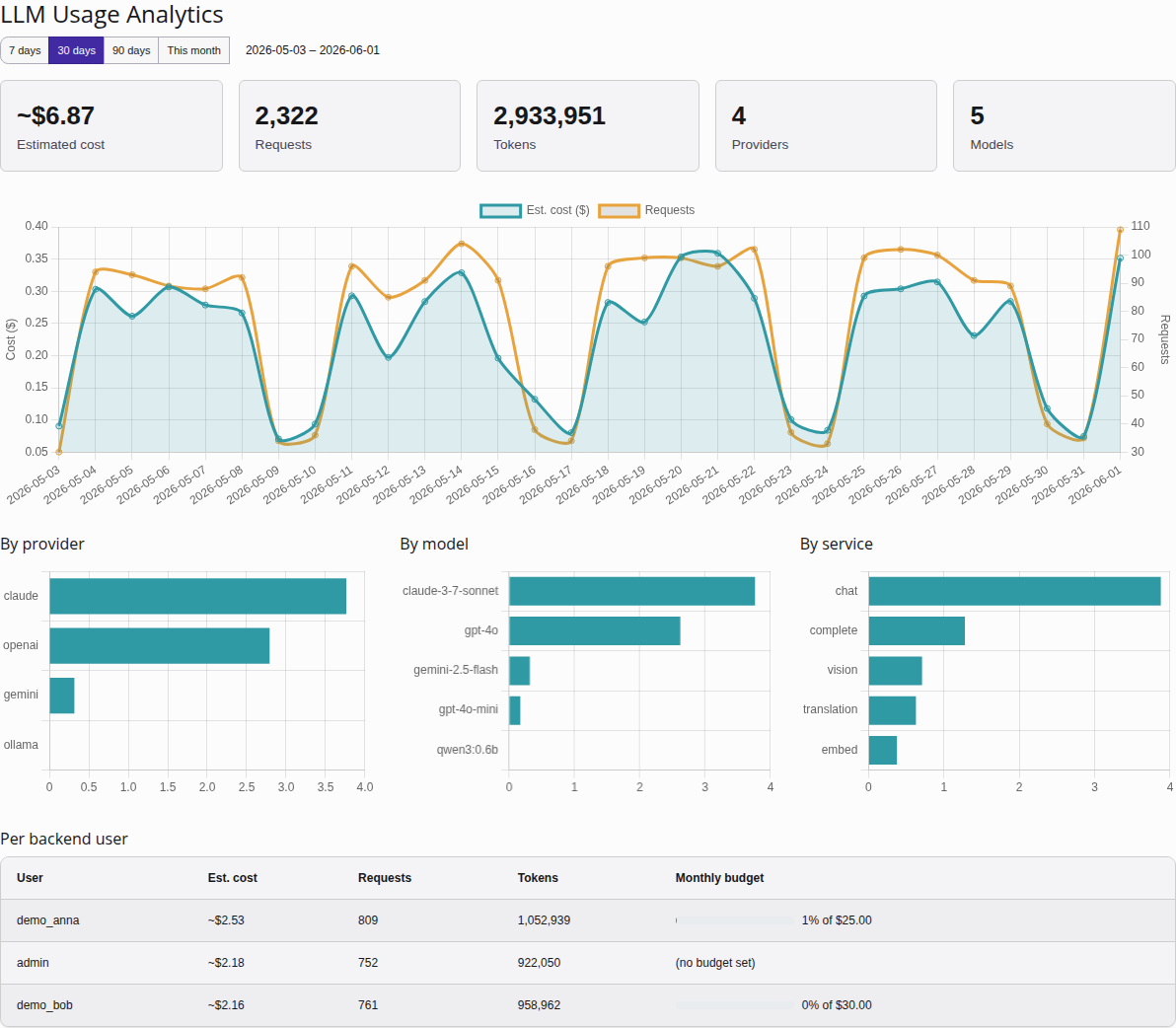
Usage analytics
The Analytics submodule turns the per-request data in
tx_nrllm_service_usage into an at-a-glance view of what your AI
spend and usage look like over time — cost and request trends,
breakdowns by provider, model, and service, and per-user consumption
against this month's budget.
The Analytics dashboard: KPI summary tiles, the cost/request trend,
the provider / model / service breakdowns, and per-user consumption
against each user's monthly budget.
Opening the module
Open Admin Tools > LLM > Analytics. The submodule sits next
to the other LLM sections in the left-hand navigation and is
admin-only, like the rest of the module.
Choosing a date range
A range switcher at the top of the page selects the reporting window.
The range is a plain ?range= link, so changing it is an ordinary
page reload — there is no AJAX. Four presets are available:
Preset
Window
7d
The last 7 days (today and the six preceding days).
30d
The last 30 days. This is the default — any unknown range
value falls back to 30d.
90d
The last 90 days.
month
From the first of the current calendar month to today.
KPI tiles
A row of tiles summarises the selected range:
Total cost — the summed estimated cost across the window.
Total requests — the number of AI requests recorded.
Total tokens — prompt plus completion tokens consumed.
Providers — how many distinct providers were used.
Models — how many distinct models were used.
These are totals for the chosen range, not all-time figures.
Cost and requests trend
A line chart plots daily estimated cost and daily request count across
the range. Days with no usage are filled in as zero so the line is
continuous rather than skipping gaps.
Breakdown charts
Three bar charts split the window's usage along different axes:
By provider — cost and requests per service_provider
(OpenAI, Anthropic, Ollama, …).
By model — cost and requests per model. This dimension is new:
it relies on the model_uid / model_id columns added to the
usage table, so it only reflects usage recorded after that change.
By service — cost and requests per service type (chat, vision,
translation, speech, image).
Per-user table
A table lists usage grouped by backend user, ordered by cost. Each row
shows the user's request count, token total, and estimated cost for the
selected range, plus a monthly-budget bar that visualises how much
of their per-user budget (see Per-user AI budgets) they
have consumed.
Note
The budget bar always reflects the current calendar month,
regardless of the date range selected above. The other columns
follow the selected range; the budget bar does not, because a
budget is a monthly ceiling.
Requests made without an authenticated backend user (CLI, scheduler,
be_user = 0) are grouped under a system row.
A note on cost
All cost figures are estimated. They are computed from the model
pricing you configured (cents per 1M tokens, applied to the recorded
prompt/completion token split), not billed back from the provider.
Treat them as a planning and trend signal, not as an invoice. Costs are
captured at call time, so they reflect the pricing in effect when each
request ran. See ADR-029: Usage Analytics Dashboard for the design rationale.
Specialized services (DALL·E, text-to-speech, Whisper, DeepL) still
record their requests and units, but their cost is currently shown as
0 — token-based pricing does not apply to them yet. Streaming
responses are not recorded at all, because chunked output has no single
terminal token count to price.
Usage columns in the list views
The Providers, Models, Configurations, and Tasks list views each carry
three extra columns — Cost (30d), Requests (30d)
and Tokens (30d) — summarising the last 30 days of usage for
that row, so you can spot the heavy hitters without leaving the list.
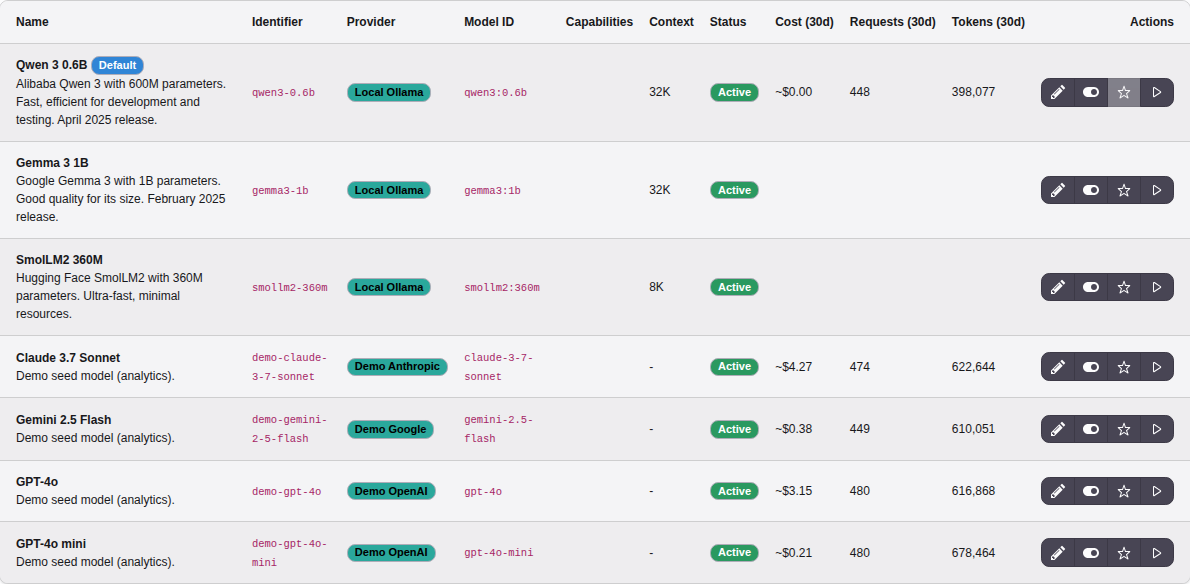
The Models list with the 30-day usage columns. Models with no usage
in the window show blank cells; free local models show ~$0.00.
Two attribution notes:
The Providers column aggregates by adapter type (the value stored
on each usage row), not by individual provider record — two providers
that share an adapter therefore show the same figures.
The Tasks column relies on per-task tracking: each task execution
records its task_uid so usage rolls up to the task that triggered
it. Calls made outside a task (direct API/service use) are not
attributed to any task row.
Demo data for local development
To populate the module with something to look at during local
development, run the dev-only DDEV command:
ddev seed-usage
Copied!
It generates roughly 90 days of realistic historic usage across
providers, models, services, and users so the trend line, breakdown
charts, and per-user table all have content. This command is for local
DDEV environments only — do not run it against production data.
Configuration reference
This page is the field reference for all
configurable entities. For step-by-step setup
instructions, see the
Administration guide.
Providers represent API connections with credentials.
Provider list showing adapter type, endpoint,
API key status, and action buttons.
Required
identifier
identifier
Type
string
Required
true
Unique slug for programmatic access
(e.g., openai-prod, ollama-local).
name
name
Type
string
Required
true
Display name shown in the backend.
adapter_type
adapter_type
Type
string
Required
true
The protocol to use:
openai — OpenAI API
anthropic — Anthropic Claude API
gemini — Google Gemini API
ollama — Local Ollama instance
openrouter — OpenRouter multi-model API
mistral — Mistral AI API
groq — Groq inference API
azure_openai — Azure OpenAI Service
custom — OpenAI-compatible endpoint
api_key
api_key
Type
string
API key for authentication. Stored as a
nr-vault
UUID identifier (envelope encryption).
nr-llm never stores raw API keys in the
database. Required for cloud providers
(OpenAI, Claude, Gemini, etc.); not required
for local providers like Ollama.
Optional
endpoint_url
endpoint_url
Type
string
Default
(adapter default)
Custom API endpoint URL.
organization_id
organization_id
Type
string
Default
(empty)
Organization ID (OpenAI, Azure).
timeout
timeout
Type
integer
Default
30
Request timeout in seconds.
max_retries
max_retries
Type
integer
Default
3
Number of retry attempts on failure.
options
options
Type
JSON
Default
{}
Additional adapter-specific options.
Model fields
Models represent specific LLM models available
through a provider.
Model list with capability badges, context
length, and cost columns.
Required
identifier (model)
identifier (model)
Type
string
Required
true
Unique slug (e.g., gpt-5, claude-sonnet).
name (model)
name (model)
Type
string
Required
true
Display name (e.g., GPT-5 (128K)).
provider
provider
Type
reference
Required
true
Reference to the parent provider.
model_id
model_id
Type
string
Required
true
The API model identifier as the provider expects
it (e.g., gpt-5.3-instant,
claude-sonnet-4-6, gemini-3-flash).
JSON object with a single key,
configurationIdentifiers, whose value is the
ordered list of other configuration identifiers
to retry against when the primary fails with a
retryable error (connection error, HTTP 5xx, or
HTTP 429 rate-limit). Non-retryable errors bubble
up unchanged. Streaming requests do not trigger
fallback — chunks cannot be replayed against a
different provider.
Identifiers are matched case-insensitively;
leave empty to disable fallback. See
Fallback chain.
Task fields
Tasks combine a configuration with a user prompt
template for one-shot AI operations.
Task list with assigned configurations.
Each task references an LLM configuration and adds
a user prompt template. The same configuration can
power multiple tasks with different prompts.
Settings
Provider configuration
Providers, models and configurations are database-backed and managed
in the LLM backend module — not via TypoScript. nr-llm does not read
plugin.tx_nrllm TypoScript settings; any such constants/setup have no
effect (this is true for both classic TypoScript templates and site sets).
To make the generic chat() / complete() entry points work without
pinning a provider per call, set up a default configuration:
Open the LLM backend module.
Create a Provider (e.g. OpenAI) and store its API key as an
nr-vault identifier — see API key protection.
Create a Model for that provider.
Create a Configuration bundling the model, then mark it
active and default.
The Setup Wizard in the module walks through these steps.
Without an active default configuration, generic calls throw
"No provider specified and no default provider configured".
Environment variables
.env
# TYPO3 encryption key (used for API key encryption)
TYPO3_CONF_VARS__SYS__encryptionKey=your-key
Copied!
Security
API key protection
Encrypted storage — API keys are stored as
vault identifiers (UUIDs) via the
nr-vault
extension, which uses envelope encryption.
nr-llm never stores raw API keys.
Database security — the database only contains
vault UUIDs, not secrets. Ensure backups are
encrypted regardless.
Backend access — restrict the LLM module to
authorized administrators.
Key rotation — re-encrypt via nr-vault's
key rotation mechanism.
Input sanitization
Sanitize user input before sending to providers:
Example: Sanitizing user input
// Strip markup and control characters from free-text input before it is// sent to a provider. (GeneralUtility::removeXSS() was removed from the// TYPO3 core and must not be used.)
$sanitizedInput = trim(strip_tags($userInput));
$response = $adapter->chatCompletion([
['role' => 'user', 'content' => $sanitizedInput],
]);
The extension uses TYPO3's caching framework with
cache identifier nrllm_responses.
No cache backend is specified — TYPO3 automatically
uses the instance's default cache backend. If your
instance has Redis, Valkey, or Memcached configured,
nr-llm uses it transparently with zero configuration.
Cache identifier: nrllm_responses
Cache group: nrllm
Default TTL: 3600 seconds (1 hour)
Embeddings TTL: 86400 seconds (24 hours)
To override the backend for this cache specifically:
PSR-14 events (BeforeRequestEvent, AfterResponseEvent) are planned
for a future release.
Best practices
Use feature services for common tasks instead of
raw LlmServiceManager.
Enable caching for deterministic operations like embeddings.
Handle errors gracefully with proper try-catch blocks.
Sanitize input before sending to LLM providers.
Validate output and treat LLM responses as untrusted.
Use streaming for long responses to improve UX.
Set reasonable timeouts based on expected response times.
Monitor usage to control costs and prevent abuse.
Streaming support
Streaming allows you to receive LLM responses incrementally as they are
generated, rather than waiting for the complete response. This improves
perceived performance for long responses.
The streamChat method returns a Generator that yields string chunks
as the provider generates them. Each chunk contains a portion of the response
text.
Providers that implement streamingcapableinterface support
streaming. Check provider capabilities before using:
Tool calling (also known as function calling) allows the LLM to request
execution of functions you define. The model decides when to call a tool
based on the conversation context.
Two mechanisms pick up your provider class. Use the attribute when
you can.
Preferred: the #[AsLlmProvider] attribute
Add the attribute to any provider class that lives under the
Netresearch\NrLlm\ namespace. The compiler pass auto-tags the
service, sets it public (so backend diagnostics can resolve it by
class name), and registers it with
LlmServiceManager in priority order:
Priority is an ordering hint only. Providers are still resolved by
their getIdentifier() at runtime. Higher priority wins when two
providers otherwise tie.
Note
The attribute scan is scoped to the Netresearch\NrLlm\
namespace to keep container-build reflection bounded.
Third-party extensions shipping providers outside that namespace
must continue to use the yaml-tagging path described below.
Third-party fallback: yaml tagging
Extensions that sit outside the Netresearch\NrLlm\ namespace
still work via the original mechanism — declare a service with the
nr_llm.provider tag:
When both yaml tagging AND the attribute are present on the same
service, the yaml wins (the attribute pass skips already-tagged
services). Treat this as an override hook rather than an additive
mechanism.
Capability interfaces
Priority governs registration order only; it says nothing about
what a provider can do. Capabilities are advertised by implementing
the relevant interface from NetresearchNrLlmProviderContract:
VisionCapableInterface — image analysis
StreamingCapableInterface — SSE streaming
ToolCapableInterface — function / tool calling
DocumentCapableInterface — PDF / structured document input
LlmServiceManager dispatches to a provider only when the
caller's requested operation matches a capability the provider
actually advertises. A provider that doesn't implement
VisionCapableInterface can never be asked to describe an
image, regardless of priority. See ADR-022: Attribute-Based Provider Registration for the
attribute-discovery design decision and the Symfony
registerAttributeForAutoconfiguration alternative we evaluated.
Fallback chain
A LlmConfiguration can carry an ordered list of other
configuration identifiers to fall back to on retryable provider
failures. The lookup happens transparently inside
NetresearchNrLlmServiceLlmServiceManager::chatWithConfiguration()
and completeWithConfiguration(). Callers see a regular
completion response or a typed exception; they never need to
reach into retry mechanics.
Configuring a chain
The tx_nrllm_configuration.fallback_chain column stores a
JSON object with a single key, configurationIdentifiers, whose
value is the ordered array of target configuration identifiers:
Editors paste that JSON into the Fallback Chain tab in
the backend form. The order is the retry order. Identifiers are
matched case-insensitively against tx_nrllm_configuration.identifier.
Using an object (rather than a bare top-level array) leaves room for
future sibling fields — e.g. per-link retry policy — without a
schema break.
Retryable vs. non-retryable errors
Fallback only triggers for errors the next provider might actually
recover from:
ProviderResponseException with code 429
(rate-limited by this provider)
Yes
ProviderResponseException with any other 4xx
(authentication, bad request, not found, …)
No. Bubbles up. A different provider with the same input
would fail the same way.
ProviderConfigurationException
No. Misconfiguration is a human problem.
UnsupportedFeatureException
No. Fallback won't make a text-only provider handle images.
When every configuration in the chain trips a retryable error,
NetresearchNrLlmProviderExceptionFallbackChainExhaustedException
is thrown. It carries the per-attempt errors so consumers can
surface the full failure sequence.
Scope limits
v1 is deliberately narrow:
No streaming.streamChatWithConfiguration() does not
wrap the call. Once the first chunk has been yielded to the
caller, mid-stream provider-switching would be detectable and
surprising.
No recursion. A fallback configuration's own chain is
ignored. This avoids cycles (a -> b -> a) and unbounded
attempt trees.
Single primary-only chain is a no-op. If the configured
chain contains only the primary's own identifier, the primary's
original exception is rethrown verbatim rather than wrapped in
FallbackChainExhaustedException.
Using the DTO directly
For programmatic construction — e.g. a wizard that generates a
configuration and also sets up fallback — use the
NetresearchNrLlmDomainDTOFallbackChain value object:
EXT:my_ext/Classes/Service/Setup.php
useNetresearch\NrLlm\Domain\DTO\FallbackChain;
$chain = (new FallbackChain())
->withLink('claude-sonnet')
->withLink('ollama-local');
$configuration->setFallbackChainDTO($chain);
Copied!
The DTO trims and lowercases identifiers on entry, deduplicates
them, and silently rejects empty strings and non-string entries
read from malformed JSON. See ADR-021: Provider Fallback Chain for the full design
rationale and the alternatives we ruled out.
BE group permission checks
Every ModelCapability enum value is registered as a native
TYPO3 customPermOptions entry under the nrllm namespace.
Administrators see a checkbox per capability (chat, completion,
embeddings, vision, streaming, tools, json_mode, audio, image,
text_to_speech, transcription) on the
Backend Users > Access Options tab when editing a BE
group. Consumer code asks the
NetresearchNrLlmServiceCapabilityPermissionService
whether the capability is allowed for the current user.
Running a check
Inject the service and call isAllowed() before dispatching.
The method accepts an optional BackendUserAuthentication for
tests; when omitted it reads $GLOBALS['BE_USER']:
EXT:my_ext/Classes/Service/Caption.php
useNetresearch\NrLlm\Domain\Enum\ModelCapability;
useNetresearch\NrLlm\Exception\AccessDeniedException;
useNetresearch\NrLlm\Service\CapabilityPermissionService;
finalclassCaption{
publicfunction__construct(
private readonly CapabilityPermissionService $permissions,
){}
publicfunctiondescribe(string $imageUrl): string{
if (!$this->permissions->isAllowed(ModelCapability::VISION)) {
thrownew AccessDeniedException(
'Vision capability not permitted for this user',
1745712100,
);
}
// ... dispatch to VisionService ...
}
}
Copied!
Resolution order
The check resolves in this order:
No BE user in context (CLI, scheduler, frontend) → allowed.
Capability gating is a backend-editor concern; background jobs
and frontend rendering are not subject to it.
User is admin → allowed. Admins bypass the native TYPO3
permission machinery by convention.
Delegates to
$backendUser->check('custom_options', 'nrllm:capability_X')
— the native TYPO3 permission check. Returns what it returns.
Complementary to configuration ACL
The allowed_groups MM relation on
tx_nrllm_configuration gates access to a specific preset
(API keys, system prompt, etc.). Capability permissions gate which
operations a user may invoke against any preset they can already
reach. The two are orthogonal and both checks must pass.
Configuration ACL: "Can this editor use the
'creative-writing' configuration at all?"
Capability permission: "Can this editor invoke vision
against any configuration?"
Stable keys
CapabilityPermissionService::permissionString() returns the
TYPO3 permission string (e.g. nrllm:capability_vision) for any
enum case. Use it when you need to check directly without going
through the service, for example in a Fluid ViewHelper or a TCA
display condition:
This guide walks you through adding AI capabilities to a TYPO3 extension using
nr-llm as a dependency. By the end, your extension will have working AI features
without any provider-specific code.
nr-llm throws typed exceptions so you can provide meaningful feedback:
Error handling with typed exceptions
useNetresearch\NrLlm\Provider\Exception\ProviderConfigurationException;
useNetresearch\NrLlm\Provider\Exception\ProviderConnectionException;
useNetresearch\NrLlm\Provider\Exception\ProviderResponseException;
try {
$response = $this->llm->complete($prompt);
} catch (ProviderConfigurationException) {
// No provider configured — guide the adminreturn'AI features require LLM configuration. '
. 'An administrator can set this up in Admin Tools > LLM.';
} catch (ProviderConnectionException) {
// Network issue — suggest retryreturn'Could not reach the AI provider. Please try again.';
} catch (ProviderResponseException $e) {
// Provider returned an error (rate limit, invalid input, etc.)$this->logger->warning('LLM provider error', ['exception' => $e]);
return'The AI service returned an error. Please try again later.';
}
Copied!
Step 5: Use database configurations (optional)
For advanced use cases, reference named configurations that admins create in the
backend module:
Using named database configurations
useNetresearch\NrLlm\Domain\Repository\LlmConfigurationRepository;
useNetresearch\NrLlm\Service\LlmServiceManagerInterface;
final readonly classBlogSummarizer{
publicfunction__construct(
private LlmConfigurationRepository $configRepo,
private LlmServiceManagerInterface $llm,
){}
publicfunctionsummarize(string $article): string{
// Uses the "blog-summarizer" configuration created by the admin// (specific model, temperature, system prompt, etc.)
$config = $this->configRepo->findByIdentifier('blog-summarizer');
$response = $this->llm->chat(
[['role' => 'user', 'content' => "Summarize:\n\n" . $article]],
$config->toChatOptions(),
);
return $response->content;
}
}
Copied!
Testing your integration
Mock the nr-llm interfaces in your unit tests:
Tests/Unit/Service/MyAiServiceTest.php
useNetresearch\NrLlm\Domain\Model\CompletionResponse;
useNetresearch\NrLlm\Domain\Model\UsageStatistics;
useNetresearch\NrLlm\Service\LlmServiceManagerInterface;
usePHPUnit\Framework\TestCase;
finalclassMyAiServiceTestextendsTestCase{
publicfunctiontestSummarizeReturnsCompletionContent(): void{
$llm = $this->createStub(LlmServiceManagerInterface::class);
$llm->method('complete')->willReturn(
new CompletionResponse(
content: 'A short summary.',
model: 'gpt-5.3-instant',
usage: new UsageStatistics(50, 20, 70),
finishReason: 'stop',
provider: 'openai',
),
);
$service = new MyAiService($llm);
self::assertSame('A short summary.', $service->summarize('Long text...'));
}
}
Copied!
Integration checklist
composer.json — Added netresearch/nr-llm to require
ext_emconf.php — Added nr_llm to depends constraints
Services — Inject LlmServiceManagerInterface
or feature services via DI
Error handling — Catch typed exceptions and show user-friendly messages
Testing — Mock LlmServiceManagerInterface in unit tests
Documentation — Tell your users they need to
configure a provider in Admin Tools > LLM
Feature services
High-level AI services for TYPO3 with prompt engineering and response parsing.
The feature services layer provides domain-specific AI
capabilities for TYPO3 extensions. Each service wraps
the core LlmServiceManager with specialized
prompts, response parsing, and configuration optimized
for specific use cases.
// Standard completion
$response = $completionService->complete($prompt);
// JSON output
$data = $completionService->completeJson('List 5 colors as a JSON array');
// Markdown output
$markdown = $completionService->completeMarkdown('Write docs for this API');
// Factual (low creativity, high consistency)
$response = $completionService->completeFactual('What is the capital of France?');
// Creative (high creativity)
$response = $completionService->completeCreative('Write a haiku about coding');
Get a specific provider by identifier. An explicit identifier is
required; passing null throws ProviderException (code
4867297358). To select a provider without naming one, pin it per
call via the options object's provider field, or configure an
active default Configuration in the backend module (see ADR-034).
param string|null $identifier
Provider identifier
(openai, claude, gemini); null is rejected
The same architecture expressed as PlantUML (for rendering with
external tools):
Three-tier configuration architecture (PlantUML)
@startuml
skinparam rectangle {
BackgroundColor<<config>> #E8F5E9
BackgroundColor<<model>> #E3F2FD
BackgroundColor<<provider>> #FFF3E0
}
rectangle "**CONFIGURATION**\n(Use-Case Specific)" <<config>> as C {
note right
blog-summarizer
product-description
support-translator
end note
}
rectangle "**MODEL**\n(Available Models)" <<model>> as M {
note right
gpt-5, claude-sonnet-4-5
llama-70b
text-embedding-3-large
end note
}
rectangle "**PROVIDER**\n(API Connections)" <<provider>> as P {
note right
openai-prod, openai-dev
local-ollama
azure-openai-eu
end note
}
C -down-> M : "N:1\nmodel_uid"
M -down-> P : "N:1\nprovider_uid"
@enduml
Copied!
Benefits
Multiple API keys per provider type:
Separate production and development accounts.
Custom endpoints: Azure OpenAI, Ollama, vLLM, local models.
Reusable model definitions: Centralized capabilities and pricing.
Clear separation of concerns: Connection vs capability vs use-case.
Provider layer
Represents a specific API connection with credentials.
Database table: tx_nrllm_provider
Field
Type
Description
identifier
string
Unique slug (e.g., openai-prod, ollama-local)
name
string
Display name (e.g., OpenAI Production)
adapter_type
string
Protocol: openai, anthropic, gemini, ollama, etc.
endpoint_url
string
Custom endpoint (empty = default)
api_key
string
nr-vault identifier (UUID) for the encrypted key
organization_id
string
Optional organization ID (OpenAI)
timeout
int
Request timeout in seconds
max_retries
int
Retry count on failure
options
JSON
Additional adapter-specific options
Key design points:
One provider = one API key = one billing relationship.
Same adapter type can have multiple providers (prod/dev accounts).
Adapter type determines the protocol/client class used.
API keys are stored as nr-vault identifiers (UUIDs); the raw key never
touches nr-llm's tables.
Model layer
Represents a specific model available through a provider.
API keys are never stored as plaintext in nr-llm's own tables. Each provider
record holds a vault identifier (UUID) issued by the nr-vault extension, which performs
envelope encryption with audited access.
The database stores only the vault UUID, never a raw key.
Retrieval and injection into outbound requests go through nr-vault's
secure, SSRF-guarded HTTP client.
# Install dependencies (dev deps included by default)
composer install
Copied!
Unit tests
Run unit tests
# Recommended: Use runTests.sh (Docker-based, consistent environment)
Build/Scripts/runTests.sh -s unit
# With specific PHP version
Build/Scripts/runTests.sh -s unit -p 8.3
# Alternative: Via Composer script
composer ci:test:php:unit
Copied!
Integration tests
Run integration tests
# Run integration tests (requires API keys)
OPENAI_API_KEY=your-api-key-here \
Build/Scripts/runTests.sh -s functional
Copied!
All tests
Run complete test suite
# Run all test suites via runTests.sh
Build/Scripts/runTests.sh -s unit
Build/Scripts/runTests.sh -s functional
# Run code quality checks
Build/Scripts/runTests.sh -s cgl
Build/Scripts/runTests.sh -s phpstan
Mock external APIs: Never call real APIs in unit tests.
Use data providers: For testing multiple scenarios.
Test edge cases: Empty inputs, null values, boundaries.
Descriptive names: Test method names should describe behavior.
Arrange-Act-Assert: Follow AAA pattern.
Fast tests: Unit tests should complete in milliseconds.
Coverage goals: Aim for >80% line coverage.
E2E testing
Overview
E2E tests verify complete workflows from service entry
point through to response handling. They use mocked HTTP
clients to simulate external API interactions without
requiring real API keys.
Tests are located in Tests/E2E/ and include:
Workflow tests — full chat completion, embedding,
and TCA field completion flows
Backend module tests — provider, model,
configuration, and task management
Playwright tests — browser-based UI tests for
the backend module
Running E2E tests
Run E2E tests
# PHP-based E2E tests (mocked HTTP, in unit suite)
Build/Scripts/runTests.sh -s unit -- Tests/E2E/
# Playwright browser E2E tests
Build/Scripts/runTests.sh -s e2e
Attach skills to tasks/configurations; compose into
the user prompt (text-gen only), budgeted and
checksum-verified.
Tools
ADR-038: Tool runtime
DI-tagged tool registry + bounded agent loop on the
config's vault key/model/pricing; allow-list gated,
admin-only.
ADR-039: Global tool availability
Site-wide per-tool enable/disable override
(tx_nrllm_tool_state, no TCA) intersected with every
run's allow-list — a hard admin kill switch.
ADR-001: Provider Abstraction Layer
Status
Accepted (2024-01)
Context
We needed to support multiple LLM providers (OpenAI,
Anthropic Claude, Google Gemini) while maintaining a
consistent API for consumers. Each provider has
different:
Capability interfaces for optional features (embeddings are a core
ProviderInterface method, not an opt-in capability):
VisionCapableInterface.
StreamingCapableInterface.
ToolCapableInterface.
DocumentCapableInterface.
AbstractProvider base class with shared functionality.
LlmServiceManager as the unified entry point.
Consequences
Positive:
●● Consumers use single API regardless of provider.
●● Easy to add new providers.
● Capability checking via interface detection.
●● Provider switching requires no code changes.
Negative:
✕ Lowest common denominator for shared features.
◑ Provider-specific features require direct provider access.
◑ Additional abstraction layer complexity.
Net Score: +5.5 (Strong positive impact -
abstraction enables flexibility and maintainability)
Alternatives considered
Single monolithic class: Rejected due to maintenance complexity.
Strategy pattern only: Insufficient for capability detection.
Factory pattern: Used in combination with interfaces.
ADR-002: Feature Services Architecture
Status
Accepted (2024-02)
Context
Common LLM tasks (translation, image analysis, embeddings) require:
Specialized prompts and configurations
Pre/post-processing logic
Caching strategies
Quality control measures
Decision
Create dedicated Feature Services for high-level operations:
CompletionService: Text generation with format control.
EmbeddingService: Vector operations with caching.
VisionService: Image analysis with specialized prompts.
TranslationService: Language translation with quality scoring.
Each service:
Uses LlmServiceManager internally.
Provides domain-specific methods.
Handles caching and optimization.
Returns typed response objects.
Consequences
Positive:
●● Clear separation of concerns.
● Reusable, tested implementations.
●● Consistent behavior across use cases.
● Built-in best practices (caching, prompts).
Negative:
◑ Additional classes to maintain.
◑ Potential duplication with manager methods.
◑ Learning curve for service selection.
Net Score: +6.5 (Strong positive impact - services
provide high-level abstractions with best practices)
ADR-003: Typed Response Objects
Status
Accepted (2024-01)
Context
Provider APIs return different response structures. We needed to:
Provide consistent response format to consumers.
Enable IDE autocompletion and type checking.
Include relevant metadata (usage, model, finish reason).
Decision
Use immutable value objects for responses:
Example: CompletionResponse value object
finalclassCompletionResponse{
publicfunction__construct(
public readonly string $content,
public readonly string $model,
public readonly UsageStatistics $usage,
public readonly string $finishReason,
public readonly string $provider,
public readonly ?array $toolCalls = null,
){}
}
Copied!
Key characteristics:
final classes prevent inheritance issues.
readonly properties ensure immutability.
Constructor promotion for concise definition.
Nullable for optional data.
Consequences
Positive:
●● Strong typing with IDE support.
● Immutable objects are thread-safe.
●● Clear API contract.
● Easy testing and mocking.
Negative:
◑ Cannot extend responses.
✕ Breaking changes require new properties.
◑ Slight memory overhead vs arrays.
Net Score: +5.5 (Strong positive impact - type
safety and immutability outweigh flexibility
limitations)
The PSR-14 events described below (BeforeRequestEvent /
AfterResponseEvent) were never implemented and no longer reflect
the code — there is no Classes/Event/ directory and
LlmServiceManager dispatches no events. The extension points this ADR
set out to provide (request modification, response processing, cost tracking,
rate limiting) are delivered instead by the provider middleware pipeline
(ADR-026): FallbackMiddleware, BudgetMiddleware,
UsageMiddleware and CacheMiddleware wrap every provider call. New
cross-cutting behaviour should be added as a middleware, not an event
listener. The original decision is kept below for historical context.
Context
Consumers need extension points for:
Logging and monitoring.
Request modification.
Response processing.
Cost tracking and rate limiting.
Decision
Use TYPO3's PSR-14 event system with events:
BeforeRequestEvent: Modify requests before sending.
AfterResponseEvent: Process responses after receiving.
Events are dispatched by LlmServiceManager and provide:
Full context (messages, options, provider).
Mutable options (before request).
Response data (after response).
Timing information.
Consequences
Positive:
●● Follows TYPO3 conventions.
●● Decoupled extension mechanism.
● Multiple listeners without modification.
● Testable event handlers.
Negative:
◑ Event overhead on every request.
◑ Listener ordering considerations.
◑ Debugging event flow complexity.
Net Score: +6.5 (Strong positive impact - standard
TYPO3 integration with decoupled extensibility)
ADR-005: TYPO3 Caching Framework Integration
Status
Accepted (2024-03)
Context
LLM API calls are:
Expensive (cost per token).
Relatively slow (network latency).
Often deterministic (embeddings, some completions).
Decision
Integrate with TYPO3's caching framework:
Cache identifier: nrllm_responses.
No backend specified — TYPO3 uses the instance's
default cache backend (respects Redis/Valkey/Memcached).
Cache keys based on: provider + model + input hash.
TTL: 3600s default (configurable).
Cache group: nrllm (flush via
cache:flush --group=nrllm).
Caching strategy:
Always cache: Embeddings (deterministic).
Optional cache: Completions with temperature=0.
Never cache: Streaming, tool calls, high temperature.
Consequences
Positive:
●● Reduced API costs.
●● Faster responses for cached content.
● Follows TYPO3 patterns.
◐ Configurable per deployment.
Negative:
✕ Cache invalidation complexity.
◑ Storage requirements.
✕ Stale responses if TTL too long.
Net Score: +4.5 (Positive impact - significant
cost/performance gains with manageable cache
complexity)
The shipped providers no longer carry an explicit tags: entry — they
self-register via the #[AsLlmProvider] attribute collected by
ProviderCompilerPass (ADR-022). The tags: form
above still works for third-party providers.
Provider selection:
Explicit provider in the per-call options.
Otherwise the active DB-backed default configuration's provider.
Otherwise getProvider(null)throws a ProviderException.
There is deliberately no "first provider by priority" fallback: the
implicit default-provider fallback was removed in ADR-034, so
provider selection is always explicit (per-call option or the active
configuration).
Consequences
Positive:
● Easy provider registration.
● Clear priority system.
●● Supports custom providers.
● Automatic fallback.
Negative:
◑ Priority conflicts possible.
◑ All providers instantiated.
◑ Configuration complexity.
Net Score: +5.5 (Strong positive impact - flexible
multi-provider support with minor overhead)
Tool calls returned in CompletionResponse::$toolCalls:
A typed list<ToolCall> (nullable) of ToolCall value objects —
each with the tool id, name and its arguments as an already
JSON-decoded associative array (not an encoded string). A full
tool-execution runtime was added later in ADR-038.
Consequences
Positive:
●● Industry-standard format.
●● Cross-provider compatibility.
● Flexible tool definitions.
● Type-safe parameters.
Negative:
◑ Complex nested structure.
◑ Provider translation needed.
✕ No automatic execution.
◑ Testing complexity.
Net Score: +5.0 (Positive impact -
OpenAI-compatible format ensures broad compatibility)
This ADR documents the original encryption approach which has been replaced.
API keys are now stored using the
netresearch/nr-vault
extension
which provides enterprise-grade secrets management with envelope encryption,
audit logging, and access control.
Context
The nr_llm extension stores API keys for various LLM
providers (OpenAI, Anthropic, etc.) in the database.
These credentials are sensitive and require protection.
Problem statement
TYPO3's TCA type=password field has two modes:
Hashed mode (default): Uses bcrypt/argon2 -
irreversible, suitable for user passwords
Unhashed mode (hashed => false): Stores
plaintext - required for API keys that must be
retrieved
API keys must be retrievable to authenticate with
external services, so hashing is not an option.
However, storing them in plaintext exposes them to:
Database dumps/backups
SQL injection attacks
Unauthorized database access
Accidental exposure in logs
Requirements
API keys must be retrievable (not hashed).
Keys must be encrypted at rest in the database.
Encryption must be transparent to the application.
Solution must work without external dependencies (self-contained).
Must support key rotation.
Backwards compatible with existing plaintext values.
Decision
Implement application-level encryption using
sodium_crypto_secretbox (XSalsa20-Poly1305) with
key derivation from TYPO3's encryptionKey.
Architecture
┌─────────────────────────────────────────────────────────────────┐
│ Backend Form │
│ (user enters API key) │
└─────────────────────────────┬───────────────────────────────────┘
│ plaintext
▼
┌─────────────────────────────────────────────────────────────────┐
│ Provider::setApiKey() │
│ ProviderEncryptionService::encrypt() │
│ │
│ 1. Generate random nonce (24 bytes) │
│ 2. Derive key from TYPO3 encryptionKey via SHA-256 │
│ 3. Encrypt with XSalsa20-Poly1305 │
│ 4. Prefix with "enc:" marker │
│ 5. Base64 encode for storage │
└─────────────────────────────┬───────────────────────────────────┘
│ "enc:base64(nonce+ciphertext+tag)"
▼
┌─────────────────────────────────────────────────────────────────┐
│ Database │
│ tx_nrllm_provider.api_key │
└─────────────────────────────────────────────────────────────────┘
The nr_llm extension needs to manage LLM configurations
for various use cases (chat, translation, embeddings,
etc.). Initially, configurations were stored in a single
table mixing connection settings, model parameters, and
use-case-specific prompts.
Problem statement
A single-table approach creates several issues:
API Key Duplication: Same API key repeated across
multiple configurations.
Model Redundancy: Model capabilities and pricing
duplicated.
Inflexible Connections: Cannot have multiple API
keys for same provider (prod/dev).
Mixed Concerns: Connection details, model specs,
and prompts intermingled.
Maintenance Burden: Changing an API key requires
updating multiple records.
Real-world scenarios not supported
Scenario
Single-Table Problem
Separate prod/dev OpenAI accounts
Must duplicate all configurations
Self-hosted Ollama + cloud fallback
Cannot model multiple endpoints
Cost tracking per API key
No clear key-to-usage mapping
Model catalog with shared pricing
Model specs repeated everywhere
Team-specific API keys
No multi-tenancy support
Decision
Implement a three-level hierarchical architecture separating concerns:
Users need to configure LLM providers, models, configurations, and tasks -- a
complex multi-step process involving endpoint URLs, API keys, model selection,
system prompts, and temperature tuning. Manual CRUD via TYPO3 list module is
error-prone and intimidating for non-technical users.
Problem statement
High barrier to entry: First-time setup requires knowledge of API
endpoints, adapter types, model capabilities, and prompt engineering.
Model discovery gap: Users don't know which models their provider offers.
Configuration quality: Hand-written system prompts are often suboptimal.
Task chain complexity: Creating a task requires a configuration, which
requires a model, which requires a provider -- four entities in sequence.
Decision
Implement an AI-powered wizard system with three wizard types:
Configuration Wizard -- Takes a natural-language
description and generates a structured
LlmConfiguration via
WizardGeneratorService::generateConfiguration().
Task Wizard -- Takes a natural-language description and generates a
complete task chain (task + configuration + model recommendation) via
WizardGeneratorService::generateTaskWithChain().
ADR-015: Type-Safe Domain Models via PHP 8.1+ Enums & Value Objects
Status
Accepted
Date
2025-12
Authors
Netresearch DTT GmbH
Context
Domain constants were stringly-typed throughout the codebase. Adapter types were
plain strings ('openai', 'anthropic'), capabilities were CSV strings in
database columns, task categories and output formats were validated ad-hoc. This
caused subtle bugs and PHPStan violations at higher analysis levels.
Problem statement
No compile-time safety: Typos like 'opanai' pass silently at runtime.
Scattered validation: Each usage site re-validated allowed values.
Missing behavior: Constants carried no associated
logic (labels, icons, defaults).
PHPStan violations: Stringly-typed comparisons defeated type narrowing.
Decision
Use PHP 8.1+ backed enums for all domain constants. Each enum provides:
A string-backed value for database/API compatibility.
Classes/Provider/AbstractProvider.php --
Adapter type matching via enum.
ADR-016: Thinking/Reasoning Block Extraction
Status
Accepted
Date
2025-12
Authors
Netresearch DTT GmbH
Context
Modern reasoning models emit structured thinking blocks alongside their final
output. Anthropic Claude uses native thinking content blocks in its API
response. DeepSeek, Qwen, and other models wrap reasoning in
<think>...</think> XML tags within the text content. These blocks should be
accessible for debugging and transparency but must not
pollute the main response.
Decision
Extract thinking blocks from LLM responses using a two-tier strategy:
Processing untyped data from JSON API responses, form submissions, and
configuration arrays requires casting mixed values to specific scalar types.
At PHPStan level 10, direct casts like (string)$mixed trigger
"Cannot cast mixed to string" errors. Each usage site would need inline type
guards, leading to repetitive boilerplate.
Problem statement
PHPStan level 10 strictness:(string)$data['key'] is forbidden on mixed.
Verbose alternatives:is_string($v) ? $v : (is_numeric($v) ? (string)$v : '')
at every call site.
Inconsistent defaults: Different code paths used
different fallback values.
Suppression temptation: Teams resort to
@phpstan-ignore instead of proper narrowing.
Decision
Extract a reusable SafeCastTrait with three static methods that handle
mixed input with sensible defaults and no PHPStan suppressions:
Static methods -- No instance state needed;
enables self::toStr() calls.
Private visibility -- Implementation detail of
the using class, not public API.
Numeric passthrough -- is_numeric() covers
int, float, and numeric strings.
Empty-string default -- Safer than null for
string contexts (concatenation, comparison).
Zero default for int/float -- Neutral value for arithmetic operations.
Complements the ResponseParserTrait in Classes/Provider/ which
serves a similar purpose for provider API response arrays but with key-based
access (getString($data, 'key')). SafeCastTrait handles standalone values.
●● PHPStan level 10 compliance without any @phpstan-ignore suppressions.
● Consistent fallback behavior across all consumers.
● Three-line methods are trivially testable and auditable.
◐ Reduces boilerplate by 5 lines per cast site.
Negative:
◑ Trait usage adds an indirect dependency (mitigated
by being a small utility).
◑ is_numeric() accepts numeric strings like "1e2" which may surprise.
Net Score: +4.5 (Positive)
Files changed
Added:
Classes/Utility/SafeCastTrait.php
Modified (consumers):
Classes/Service/WizardGeneratorService.php --
Uses SafeCastTrait for JSON normalization.
Classes/Controller/Backend/TaskWizardController.php
-- Uses SafeCastTrait for form data casting (the monolithic
TaskController was split per ADR-027).
ADR-018: Multi-Provider Model Discovery
Status
Accepted
Date
2025-12
Authors
Netresearch DTT GmbH
Context
Different LLM providers expose different model listing APIs. OpenAI offers
GET /v1/models, Ollama uses GET /api/tags, Anthropic has no public
listing endpoint, and Gemini uses a different URL structure entirely. The
setup wizard needs a unified way to discover available models regardless of
provider.
Problem statement
Heterogeneous APIs: No standard protocol for model listing.
Authentication variance: Bearer tokens, API key headers, URL parameters.
Response format divergence: Each provider returns
different JSON structures.
Offline providers: Some providers (Anthropic,
Azure) lack public model list APIs.
Endpoint normalization: Users enter URLs
with/without trailing slashes, versions, schemes.
Decision
Abstract model discovery behind
ModelDiscoveryInterface with two operations:
The backend module needs multi-language support for all
UI elements. Additionally, LLM-powered features (test
prompts, wizard descriptions) should respect the backend
user's locale so that responses arrive in the expected
language.
Decision
Follow TYPO3 XLIFF conventions for static UI strings and add locale-aware
placeholder substitution for dynamic LLM interactions.
XLIFF label files
One XLIFF file per backend module, plus German translations:
File
Scope
locallang.xlf / de.locallang.xlf
Shared labels, flash messages
locallang_tca.xlf / de.locallang_tca.xlf
TCA field labels and descriptions
locallang_mod.xlf / de.locallang_mod.xlf
Main module navigation
locallang_mod_provider.xlf / de.*
Provider sub-module
locallang_mod_model.xlf / de.*
Model sub-module
locallang_mod_config.xlf / de.*
Configuration sub-module
locallang_mod_task.xlf / de.*
Task sub-module
locallang_mod_wizard.xlf / de.*
Setup Wizard sub-module
locallang_mod_overview.xlf / de.*
Overview/Dashboard sub-module
Locale-aware LLM features
The TestPromptResolverService (a final readonly class implementing
TestPromptResolverInterface, injected via DI — it replaced the former
TestPromptTrait when the logic was extracted out of the controller) resolves
the backend user's language and substitutes a {lang} placeholder in
configurable test prompts:
TestPromptResolverService locale resolution
publicfunctionresolve(): string{
// Reads the configurable prompt (default: "Say hello and introduce// yourself in one sentence. Respond in {lang}.") and the BE user's language.
$prompt = $this->loadConfiguredPrompt();
$languageName = self::LANGUAGE_MAP[$this->resolveBackendUserLanguage()] ?? 'English';
return str_replace('{lang}', $languageName, $prompt);
}
Copied!
Language mapping covers 27 locales (English, German, French, Spanish, Italian,
Dutch, Portuguese, Danish, Swedish, Norwegian, Finnish, Polish, Czech, Slovak,
Hungarian, Romanian, Bulgarian, Croatian, Slovenian, Greek, Turkish, Russian,
Ukrainian, Chinese, Japanese, Korean, Arabic) with English as fallback.
The test prompt text itself is configurable via TYPO3 extension configuration
($GLOBALS['TYPO3_CONF_VARS']['EXTENSIONS']['nr_llm']['testing']['testPrompt']),
allowing administrators to customize it while preserving
the {lang} placeholder.
Consequences
Positive:
●● Standard TYPO3 XLIFF approach ensures compatibility with the Translation
Handling system and third-party translation tools.
● German translations shipped as first non-English locale.
● Locale-aware test prompts produce responses in the user's language.
◐ Configurable test prompt allows site-specific customization.
◐ {lang} placeholder pattern is extensible to other features.
Negative:
◑ Additional XLIFF files increase maintenance surface per feature.
◑ Language name mapping requires manual updates for new TYPO3 locales.
Net Score: +5.0 (Strong positive)
Files changed
Added:
Resources/Private/Language/locallang.xlf and de.locallang.xlf
Resources/Private/Language/locallang_tca.xlf
and de.locallang_tca.xlf
Resources/Private/Language/locallang_mod.xlf
and de.locallang_mod.xlf
Resources/Private/Language/locallang_mod_provider.xlf and de.*
Resources/Private/Language/locallang_mod_model.xlf and de.*
Resources/Private/Language/locallang_mod_config.xlf and de.*
Resources/Private/Language/locallang_mod_task.xlf and de.*
Resources/Private/Language/locallang_mod_wizard.xlf and de.*
Resources/Private/Language/locallang_mod_overview.xlf and de.*
Classes/Service/TestPromptResolverService.php and
Classes/Service/TestPromptResolverInterface.php
ADR-020: Backend Output Format Rendering
Status
Accepted
Date
2025-12
Authors
Netresearch DTT GmbH
Context
LLM responses can contain markdown, HTML, JSON, or plain text depending on the
task's output format. Users need to view output in an appropriate rendering
mode without re-executing the (potentially expensive) LLM call.
Decision
Store raw LLM output and handle format rendering entirely client-side. The
toggle between formats is ephemeral (not persisted) and operates on the
cached raw content.
Four rendering modes in
Resources/Public/JavaScript/Backend/TaskExecute.js:
LLM responses are untrusted external content. Each mode uses a different
security strategy:
Plain/JSON: Content set via textContent
(automatic HTML escaping by the DOM).
Markdown: Content is first HTML-escaped via
escapeHtml() (textContent assignment to a
temporary element, then read back via
innerHTML). Markdown regex transforms operate on
already-escaped content, making injection safe.
HTML: Rendered inside a fully sandboxed
<iframe sandbox=""> which blocks all scripting,
form submission, and parent page access. A fixed
height of 400px is used since contentDocument is
inaccessible in sandbox mode.
The active format is initialized from the task's output_format setting
(returned by the server in the AJAX response) and can be switched by clicking
format toggle buttons. The toggle updates _activeFormat, re-renders from
_rawContent, and highlights the active button. Clipboard copy always uses
the raw content regardless of active rendering mode.
Consequences
Positive:
●● No server round-trip needed to switch display formats.
● XSS prevention for all four rendering modes via
distinct security strategies.
● Raw content preserved for clipboard copy regardless of rendering.
◐ Format toggle state is ephemeral, avoiding unnecessary persistence.
◐ Markdown renderer is lightweight (regex-based, no external library).
Negative:
◑ Markdown regex renderer is simplified (no tables,
no nested lists, no links).
◑ HTML iframe height is fixed at 400px (cannot auto-resize in sandboxed mode).
Resources/Private/Templates/Backend/Task/Execute.html
-- Format toggle UI and output container.
Classes/Controller/Backend/TaskExecutionController.php
-- Returns outputFormat in the AJAX response (the monolithic
TaskController was split per ADR-027).
Classes/Domain/Enum/TaskOutputFormat.php
-- Defines valid output formats with content types.
ADR-021: Provider Fallback Chain
Status
Accepted
Date
2026-04
Authors
Netresearch DTT GmbH
Context
A single misbehaving provider (OpenAI rate-limit, Claude outage, local Ollama
daemon not running) previously bubbled up as an uncaught exception to every
consuming extension. Operators had no built-in way to degrade gracefully to a
second or third provider.
Decision
A configuration's fallback_chain column stores an ordered JSON list of
other LlmConfiguration identifiers. On retryable failures during
LlmServiceManager::chatWithConfiguration() or
completeWithConfiguration(), FallbackMiddleware (a stage of the
provider middleware pipeline, ADR-026) walks the chain and
returns the first successful response — or throws
FallbackChainExhaustedException carrying every attempt error.
"Retryable" is narrowly defined: the request might succeed against a
different provider.
ProviderResponseException with HTTP code 429 — this provider is
rate-limiting us, another might not be
Everything else (authentication, bad request, unsupported feature,
misconfiguration) bubbles up unchanged — a different provider won't help.
Scope limitations (v1)
Streaming is not wrapped. Once the first chunk has been yielded, we
cannot swap providers mid-stream. streamChatWithConfiguration()
calls the primary adapter directly.
Shallow only. A fallback configuration's own chain is ignored. This
prevents both cycles (a -> b -> a) and exponential blow-up of attempts.
Inactive fallbacks are skipped, not treated as failures.
Missing identifiers are skipped with a warning log, not treated as
failures. Misconfiguration should not mask outages.
Storage
The chain is stored as a single JSON column to keep the schema change
minimal and avoid an additional relation table. The
Netresearch\NrLlm\Domain\DTO\FallbackChain value object handles
serialization, deduplication, and order preservation.
TCA presents the field as a JSON textarea for v1. A richer UI (sortable
multi-select of available configurations) can replace the textarea without
schema or API change.
Alternatives considered
Fat middleware pipeline (as in b13/aim). Rejected for this release —
too invasive for a single-feature change. The middleware pattern remains
on the roadmap as a v1.0 refactor; a fallback chain is the most valuable
pipeline step users ask for and works fine as a standalone service.
Recursive chain resolution (fallback's fallback). Rejected as the
cost (cycle detection, attempt amplification) outweighs the benefit;
operators can always append to the primary's chain directly.
Per-link retry policy (per fallback: max retries, backoff, which
exceptions). Rejected as over-engineered for the initial release.
ADR-022: Attribute-Based Provider Registration
Status
Accepted
Date
2026-04
Authors
Netresearch DTT GmbH
Context
Registering a new provider previously required two places to stay in sync:
the class itself, and a tags: block in Configuration/Services.yaml
naming nr_llm.provider with a numeric priority. Omit either side and the
provider silently vanished from LlmServiceManager::getProviderList().
For the seven shipped providers this is a footgun we kept stepping on during
refactors. For third-party providers it is an onboarding tax.
Decision
Introduce #[AsLlmProvider(priority: N)] on the provider class and have
ProviderCompilerPass scan every container definition at compile time
for the attribute, auto-tagging matched services with nr_llm.provider.
The existing yaml-tagging path still works. When both are present, the yaml
tag wins (the attribute pass skips already-tagged services). This is
deliberate: overrides should be explicit, not silently merged.
The shipped providers now declare their priority via the attribute, and the
tags: entries have been removed from Configuration/Services.yaml.
ProviderCompilerPass collects every nr_llm.provider-tagged service
(from the attribute or a legacy yaml tag), sorts them by priority, and wires
each one into LlmServiceManager with a registerProvider() method
call. The providers stay private — they are never individually resolved
from the container (which keeps the public-services set locked by
ADR-028); the backend instantiates the concrete adapter for a
provider record directly through ProviderAdapterRegistry. The legacy
yaml-tagging path still works for third-party providers.
Trade-offs
+ Single source of truth. The priority lives next to the class, not in
a sibling yaml file.
+ Third-party DX. External providers drop in without editing yaml:
#[AsLlmProvider(priority: 100)] on an autowired class is enough.
- Reflection at compile time. The compiler pass reflects service
definitions in the Netresearch\NrLlm\ namespace; other definitions
are skipped by a prefix match on the class name (no reflection). Cost
is paid once per container build, cached via
ContainerBuilder::getReflectionClass(), and negligible in
practice.
- Implicit registration. A new reader grepping nr_llm.provider in
yaml no longer finds all providers. Mitigation: the attribute constant
AsLlmProvider::TAG_NAME is discoverable via symbol search.
Alternatives considered
Symfony's ``registerAttributeForAutoconfiguration`` — the idiomatic
path, but TYPO3's DI bootstrap does not expose the underlying container
builder at a hook point where attribute registration would work cleanly
for every installed extension. A compiler pass runs at the right
lifecycle stage and touches only our tag.
Keep yaml tags only. Rejected: the double-bookkeeping problem was the
whole motivation.
Scan providers directory by namespace. Rejected as too magical —
implicit "any class ending in Provider" registration is a known anti-pattern.
ADR-023: Native Backend Capability Permissions
Status
Accepted
Date
2026-04
Authors
Netresearch DTT GmbH
Context
Until now, the only gate on who could invoke an AI capability (vision,
tools, embeddings, ...) was the per-configuration allowed_groups MM
relation. That is coarse: an editor with access to the "creative writing"
configuration could invoke any of its capabilities — text, tool-calling,
embeddings — even if the administrator only intended them to use chat.
Administrators also had no native UI surface to revoke a single capability
site-wide without editing every affected configuration.
Decision
Register every ModelCapability enum value as a native TYPO3 BE group
permission under
$TYPO3_CONF_VARS['BE']['customPermOptions']['nrllm']. The BE group
edit view now shows a checkbox for every ModelCapability case (11 today:
chat, completion, embeddings, vision, streaming, tools, json_mode, audio, image,
text_to_speech, transcription). A new service,
CapabilityPermissionService, resolves the check against the
currently logged-in backend user.
Resolution order:
No BE user in context (CLI, scheduler, frontend) — allowed.
User is admin — allowed.
Otherwise — delegate to
$backendUser->check('custom_options', 'nrllm:capability_X').
Scope
This ADR ships the registration + check primitive. It does NOT
retroactively gate calls inside CompletionService, VisionService,
etc. — that is a deliberate follow-up concern, because it is a larger
behavioural change than a single-PR feature warrants.
Consumers can opt in today:
if (!$this->capabilityPermissions->isAllowed(ModelCapability::VISION)) {
thrownew AccessDeniedException('Vision capability not permitted for this user', 1745712100);
}
Copied!
Relation to existing access control
allowed_groups on tx_nrllm_configuration gates access to a named
configuration (API keys, preset parameters, system prompt). Capability
permissions gate which operations a user is allowed to invoke against
any configuration they already have access to. The two are complementary:
Configuration ACL: "Can this editor use the 'creative-writing'
configuration at all?"
Capability permission: "Can this editor invoke vision against any
configuration?"
Both checks must pass.
Alternatives considered
Per-capability flags ontx_nrllm_configuration. Rejected:
capability is an editor-role concern, not a configuration concern.
Duplicating the checkbox on every row is worse UX than a single
per-group toggle.
A sibling MM table (configuration-to-capability). Rejected as
another bespoke access model on top of TYPO3's native one. The whole
point of this ADR is to use the native mechanism.
Inject the check into every feature service now. Rejected to keep
the PR small and the regression surface narrow. See the Scope note
above — follow-up work.
ADR-024: Dashboard Widgets
Status
Accepted
Date
2026-04
Authors
Netresearch DTT GmbH
Context
tx_nrllm_service_usage has tracked per-request cost and usage from day
one, but the data was only reachable through the backend module's report
views. Administrators wanted an at-a-glance view next to everything else
they already follow — scheduled tasks, indexing, form submissions — which
lives on TYPO3's dashboard.
Decision
Ship two widgets that reuse TYPO3's built-in widget classes and wire them
up with nr-llm-specific data providers:
AI cost this month — NumberWithIconWidget backed by
MonthlyCostDataProvider, which delegates to
UsageTrackerService::getCurrentMonthCost(). Returns dollars
floored to an integer; the dashboard tile is a glance-value, not an
accounting figure.
AI requests by provider (7d) — BarChartWidget backed by
RequestsByProviderDataProvider, which aggregates every service
type (chat, vision, translation, speech, image) by service_provider
over the last seven days.
Both are registered in a dedicated Configuration/Services.Dashboard.php
imported conditionally from Configuration/Services.php only when
interface_exists(TYPO3\CMS\Dashboard\Widgets\WidgetInterface::class).
A PHP config file (not YAML) is used so the import can be guarded by that
runtime interface_exists() check. Without the guard, TYPO3 instances that
do not have typo3/cms-dashboard installed would fail at container
compile time on the unresolved widget class.
Classes/Widgets/* is excluded from the global auto-registration in
Services.yaml for the same reason — the data provider classes
import dashboard interfaces and must not be loaded when dashboard is
absent.
Trade-offs
+ Reuse core widget classes. Two core TYPO3 widget types cover the
useful shapes. Writing a custom widget buys nothing.
+ Optional dependency.typo3/cms-dashboard is a suggest,
not a hard require. Installs without dashboard lose the widgets but
pay no runtime cost and see no container errors.
- Two data-shape spots. The row-shaping logic on
RequestsByProviderDataProvider::shapeChartData() is static for
unit-testability, but the SQL lives in an instance method bound to
ConnectionPool. The trade-off keeps unit tests honest and
functional coverage narrow.
- Flooring the cost. Displaying $12.97 as 12 is
jarring for cost-sensitive users but the widget API returns int.
Follow-up: a custom template could render the subtitle with fractional
digits once we have one.
Alternatives considered
Custom widget classes implementing WidgetInterface directly.
Rejected — duplicates what the core widgets already do.
Per-day time series instead of per-provider aggregate. Interesting
but the current 7-day window is short enough that the distribution is
the more useful glance value.
One combined widget with cost + count + top provider in a single
tile. Rejected — mixes two summary numbers into one, and forcing both
to share the NumberWithIconWidget shape cripples both.
ADR-025: Per-User AI Budgets
Status
Accepted
Date
2026-04
Authors
Netresearch DTT GmbH
Context
LlmConfiguration already exposes max_requests_per_day,
max_tokens_per_day and max_cost_per_day — but those limits are
per configuration, not per editor. Two editors sharing the same
preset burn through the same bucket. Administrators asked for a separate
dimension: cap editor A's spending independently of editor B's, regardless
of which configuration they pick.
Decision
Ship a new tx_nrllm_user_budget table keyed uniquely on
be_user. Each row carries six independent ceilings: requests / tokens
/ cost, times daily / monthly. 0 on any axis means "unlimited on
that axis". The record is a ceiling, not a counter — actual usage is
aggregated on demand from tx_nrllm_service_usage, the same table
the usage tracker already writes to, so there is no second write per
request and no opportunity for the two sources to drift.
BudgetService::check($beUserUid, $plannedCost) is a pure
pre-flight. It does not increment anything. Callers invoke it before
dispatching to the provider, receive a BudgetCheckResult that says
allowed / denied + which bucket was tripped, and act accordingly.
Otherwise: evaluate the daily bucket, then the monthly bucket. The
first to exceed wins and is reported; daily trips take precedence over
monthly.
The incoming call adds +1 to the request count and +plannedCost
to the cost figure before comparison, so a user at exactly the
limit is still allowed one more call.
Scope
Matches the pattern established for capability permissions (ADR-023):
this ADR ships the table + model + repository + check primitive.
Wiring BudgetService::check() into individual feature services
(CompletionService, VisionService, ...) is a follow-up.
Relation to existing limits
tx_nrllm_configuration.max_*_per_day remain in place and are
orthogonal:
Per-configuration daily limits cap a preset. Useful to stop
"expensive-model" presets from burning through budget even if many
editors share them.
Per-user budgets cap a person across every preset. Useful to
stop a specific account from running away, whichever preset they pick.
Both checks must pass. Future consumers who want both will check both.
Alternatives considered
Counter-style table (increment on every request). Rejected:
duplicates tx_nrllm_service_usage, introduces a second write per
request, and adds the drift-between-counters failure mode we deliberately
avoid.
Group-level budgets via MM to be_groups. Rejected for v1 —
individual-user budgets solve the common ask first. Group-level can
layer on later.
Auto-throttling (queue + retry when over budget). Rejected —
silent throttling is worse UX than an explicit denial with a reason
the caller can surface.
ADR-026: Provider Middleware Pipeline
Status
Accepted
Date
2026-04
Authors
Netresearch DTT GmbH
Context
Every provider call in the extension is wrapped by the same
cross-cutting concerns — or rather, it should be, but today those
concerns are scattered:
FallbackChainExecutor (Classes/Service/FallbackChainExecutor.php)
is a try primary / catch / foreach fallbacks loop with two retryable
exception types hardcoded. It has no pre/post hooks and no composition
seam.
It is applied only to database-backed configuration paths in
LlmServiceManager::runWithFallback(). Direct calls — chat(),
complete(), embed(), vision() — bypass it entirely, which
silently splits retry semantics.
BudgetService::check() (ADR-025) and
UsageTrackerService::trackUsage() are primitives that no feature
service actually calls. Budget enforcement and usage accounting must
be remembered by every caller, which is a silent footgun.
HTTP-level retry with back-off lives inside AbstractProvider
(sendRequest()). That is the wrong layer — a rate-limited provider
should be swapped, not retried in-place.
Cache lookup exists only inside EmbeddingService as ad-hoc
branches. There is no way to plug it in for deterministic completion
scenarios (seed / temperature 0) without duplicating the branch.
The end result is that every new cross-cutting requirement — PII
redaction, prompt logging, trace correlation, per-provider rate limits,
circuit breakers, a cost calculator — forces either a bespoke branch in
every feature service or a subclass of one of the god classes.
Decision
Introduce a PSR-15-inspired middleware pipeline under
Classes/Provider/Middleware/:
an immutable ProviderCallContext (operation kind, correlation
id, metadata map),
the current LlmConfiguration,
a $next callable that continues the pipeline.
and decides whether to pass through, short-circuit, swap the
configuration, or wrap the call with before/after logic.
MiddlewarePipeline::run() composes an ordered stack of them
around a terminal callable in classic onion fashion — the
first-registered middleware is the outermost layer.
The payload — messages, embedding input, tool specs, vision content —
stays captured in the terminal callable. That keeps the existing typed
response objects (CompletionResponse, EmbeddingResponse,
VisionResponse) intact on the return side and avoids inventing a
generic ProviderRequest envelope that would then have to know about
every operation variant.
Registration
Implementations are discovered via the nr_llm.provider_middleware
tag, which AutoconfigureTag applies automatically to every class
that implements the interface. The pipeline's constructor injects the
collected middleware via AutowireIterator. Ordering follows tag
priority; priority is an ordering hint only.
Contributors can add behaviour without touching Services.yaml —
implement the interface, drop the class under
Classes/Provider/Middleware/, you are done.
Scope of this ADR
Infrastructure only. No behaviour change in this PR:
FallbackChainExecutor stays untouched. Feature services continue
to work exactly as they do today. The pipeline is opt-in: consumers
have to build a terminal callable and call MiddlewarePipeline::run()
to use it.
Follow-ups
Each item below is a separate PR that lands one behaviour at a time, so
the test matrix keeps green end-to-end:
FallbackMiddleware — port FallbackChainExecutor to the
interface. LlmServiceManager::runWithFallback() stops
instantiating the executor directly and runs the pipeline instead.
Retry semantics become identical for every call path, not just
database-backed ones. Deprecate the standalone executor.
BudgetMiddleware — call BudgetService::check() before
$next; throw a typed BudgetExceededException on denial so
controllers can report which bucket tripped.
UsageMiddleware — after $next returns, hand the response to
UsageTrackerService::trackUsage(). Centralises cost/token
accounting regardless of which feature called in.
CacheMiddleware — opt-in per operation via
ProviderOperation. Embedding lookups start going through it;
the branch currently inside EmbeddingService comes out.
Direct-method wiring (centralised) — every direct API method on
LlmServiceManager (chat, complete, embed,
vision, chatWithTools) builds its terminal callable and
invokes the pipeline via a synthesised transient
LlmConfiguration. Because every feature service
(CompletionService, EmbeddingService,
TranslationService, VisionService) delegates to these
methods, feature-service traffic inherits the full middleware stack
without each service owning its own pipeline glue.
The transient configuration is unpersisted (no uid), carries an
empty fallback chain (so FallbackMiddleware passes through
verbatim), and uses a human-readable ad-hoc:<operation>:<provider>
identifier so log / trace labels distinguish direct traffic from
configuration-backed calls. Middleware that needs more context
(beUserUid for BudgetMiddleware, cache keys for
CacheMiddleware) reads it from the
ProviderCallContext metadata, not from the configuration.
Streaming (streamChat / streamChatWithConfiguration)
deliberately stays out of the pipeline per the ADR's original scope:
once the first chunk has been emitted, we cannot swap providers
mid-stream, and most middleware assume a single terminal result.
Why the centralised form rather than "every feature service owns
glue": the ADR's problem statement explicitly identifies direct
calls as the bug ("chat(), complete(), embed(),
vision() — bypass [the fallback executor] entirely, which
silently splits retry semantics"). Wiring feature services only
would have left direct LlmServiceManager callers still
bypassing the pipeline. Centralising on LlmServiceManager
fixes both in one step and keeps feature services free of pipeline
concerns.
Each follow-up is scoped to a single concern and keeps the codebase
shippable after every step.
Embedding cache migration — done
The inline cache branch that used to live in EmbeddingService::embedFull()
has been moved behind CacheMiddleware:
EmbeddingResponse and UsageStatistics grew toArray()
/ fromArray() helpers so the typed response can round-trip through
CacheMiddleware (which persists array<string, mixed> via
the TYPO3 cache frontend).
LlmServiceManager::embed() derives a stable cache key via
CacheManagerInterface::generateCacheKey() (same hash shape the
old inline branch produced, so existing cache entries stay valid) and
places it on the ProviderCallContext metadata under
CacheMiddleware::METADATA_CACHE_KEY. cache_ttl == 0
(EmbeddingOptions::noCache()) omits the key so the middleware
is a no-op — consistent with the old cacheTtl semantics.
The terminal now returns $response->toArray(); the manager
reconstructs the typed EmbeddingResponse via
EmbeddingResponse::fromArray before returning to the caller.
Public method signature is unchanged.
UsageMiddleware learned to also recognise the array-payload
shape (['usage' => [...], 'provider' => '...']) so usage
accounting stays consistent whether the pipeline produced a typed
response (other operations) or an array (embeddings via
CacheMiddleware).
EmbeddingService no longer depends on
CacheManagerInterface; it is a pure vector-math façade on top
of LlmServiceManager::embed().
Diagnostic / connectivity calls intentionally bypass the pipeline
Three controller actions test provider connectivity by calling an
adapter capability method directly, with their own try / catch
block; none of them go through MiddlewarePipeline::run().
The exact call paths today are:
ProviderController::testConnectionAction →
ProviderAdapterRegistry::testProviderConnection() →
ProviderInterface::testConnection(). The registry method
catches Throwable and runs an inline preg_replace over
$e->getMessage() to strip key / api_key / token /
secret / access_token query parameters before returning a
{success: false, message} shape. The regex mirrors what
AbstractProvider::sanitizeErrorMessage() does for
inside-provider errors but is implemented locally to keep the
registry independent of the provider base class.
ConfigurationController::testConfigurationAction →
ProviderAdapterRegistry::createAdapterFromModel() →
ProviderInterface::complete(). A short test prompt is sent
with the configuration's options. Sanitization happens at the
catch (ProviderResponseException $e) arm — by that point the
message has already been sanitised by
AbstractProvider::sanitizeErrorMessage() inside the adapter
before the exception was thrown, so the controller surfaces the
upstream HTTP status verbatim.
ModelController::testModelAction →
ProviderAdapterRegistry::createAdapterFromModel() →
ProviderInterface::complete() with a 100-token cap. Same
exception-arm sanitization story as the configuration test.
In every case the bypass is deliberate:
Budget — a connectivity / configuration probe must not be
charged against a user's monthly bucket. These are backend-admin
actions; they have no end-user budget owner.
Usage — recording a probe in the usage table would distort
cost / token dashboards. Probes are administrative, not productive
traffic.
Fallback — a probe must surface the failure of the probed
provider. Silently swapping to a healthy alternative would mask the
very condition the probe was designed to detect.
Cache — caching the result of a probe would defeat the purpose
of probing.
Together with streaming (see Follow-ups step 5 — once
the first chunk has been emitted we cannot swap providers
mid-stream, and most middleware assume a single terminal result),
these three diagnostic actions are the documented exemptions from
the "productive provider calls go through the pipeline" rule. There
are no others. New diagnostic / health-check entry points should
follow the same pattern as the three listed here: build the adapter
via ProviderAdapterRegistry, call the capability method
directly, sanitize and surface the error themselves. New
non-streaming productive entry points must go through
MiddlewarePipeline::run().
Alternatives considered
Per-operation pipelines (separate middleware stacks for chat /
embed / vision / tools). Rejected: every middleware we can foresee
— fallback, budget, usage, cache, retry, tracing — wants to run for
multiple operations. Filtering inside a middleware via
ProviderCallContext::operation is cheaper than maintaining N
parallel stacks.
Generic ``ProviderRequest`` envelope with a mixed $payload.
Rejected: forces every provider / middleware / test to downcast
payloads. Keeping the payload inside the terminal closure preserves
the typed signatures already defined by ProviderInterface and
the capability interfaces.
PSR-15 directly (ServerRequestInterface / ResponseInterface
shapes). Rejected: HTTP semantics do not fit an LLM call, mapping
OpenAI's message array onto a ServerRequestInterface is lossy,
and the extension already owns LlmConfiguration and typed
response objects that are a better fit than a generic PSR-7 request.
Event dispatcher (PSR-14) pre/post hooks. Rejected: events cannot
short-circuit, cannot substitute the call target, and cannot return a
response to the caller — all three are load-bearing for fallback and
cache middleware.
References
Audit (2026-04-23): claim #1 — "No middleware pipeline — cross-cutting
concerns are scattered or absent". Locally stored under
claudedocs/audit-2026-04-23-architecture.md.
ADR-021 — Provider Fallback Chain (the behaviour this pipeline will
eventually subsume).
ADR-025 — Per-User AI Budgets (budget primitive to be wired via
BudgetMiddleware).
ADR-027: Split TaskController
Status
Accepted
Date
2026-04
Authors
Netresearch DTT GmbH
Context
Classes/Controller/Backend/TaskController.php has grown to 920
lines carrying eleven public actions, nine private helpers, and three
distinct user-facing pathways:
List / catalog — listAction().
AI wizard (create a Task from a natural-language description) —
wizardFormAction(), wizardGenerateAction(),
wizardGenerateChainAction(), wizardCreateAction().
Execution (run a stored Task with various input sources) —
executeFormAction(), executeAction(),
refreshInputAction().
Record picking (browse DB tables to source Task input from a
record) — listTablesAction(), fetchRecordsAction(),
loadRecordDataAction().
The 2026-04 architecture audit — generated locally and kept under the
gitignored claudedocs/ directory rather than checked in (the
codebase intentionally excludes Claude Code working notes from version
control via .gitignore) — flagged three concrete problems with the
controller as it stands:
Inline SQL. Eight call sites use ConnectionPool /
QueryBuilder directly to query sys_log, the picked
record's table, and so on. Repository layer is bypassed.
Inconsistent response shape. Most backend controllers return
typed Response/* DTOs (ToggleActiveResponse,
TestConfigurationResponse, etc.) — see ADR-024 widget pattern
and the ConfigurationController precedent. TaskController's
AJAX actions instead return raw new JsonResponse(['success'
=> …, 'error' => …]) literals at sixteen call sites.
God-class scope. Three independent user pathways (catalog,
wizard, execution + record picking) sharing one class makes
navigation, testability, and per-feature ownership harder than it
needs to be.
Adding any of the planned follow-ups — pre-flight budget gating in the
execute flow (REC #4), a typed exception layer for execute errors
(REC #8), domain-JSON-to-DTO promotion for Task::getInputConfig()
(REC #6) — would each make this class even larger.
The audit explicitly noted that REC #5 should ship behind an ADR
because the change touches backend module routing, the AJAX URL surface
JavaScript depends on, and the boundary between controllers and the
service layer.
Decision
We will adopt a hybrid split: per-pathway controllers + service
extraction + uniform typed responses. Concretely:
Per-pathway controllers
The eleven public actions move into four focused controllers, each
sharing the same dependency-injection patterns we already use for
ConfigurationController / ProviderController /
ModelController:
Each controller is #[AsController] and remains thin: parse the
request DTO, delegate to a service, return a typed response.
Service extraction
Two new application services capture the logic the controllers
currently embed:
Service/Task/TaskInputResolverInterface (with
TaskInputResolverfinal readonly impl) — owns the
four "where does the input text come from" branches that today
live as getInputData(), getSyslogData(),
getDeprecationLogData(), getTableData() private
helpers. Each branch becomes an injectable strategy (or a
match over a typed source enum, depending on shape after
closer inspection).
Service/Task/TaskExecutionServiceInterface (with
TaskExecutionService impl) — coordinates: resolve input via
TaskInputResolver, render the prompt template via the existing
PromptTemplateService, dispatch to LlmServiceManager, return
a typed result DTO. This is also the hook for the future REC #4
budget pre-flight.
Repository layer
Inline SQL moves to repository methods on two repositories:
Domain/Repository/TaskRepository gains
fetchSampleRecords(string $table, ...) and
loadRecordRow(string $table, int $uid) for the picker
controller.
The sys_log and deprecation-log reads (which are
TYPO3-internal, not Task-domain) move into a small
Service/Task/TaskInputResolver collaborator that wraps the
appropriate ConnectionPool /
Filesystem calls in named methods, then is exposed via an
interface so tests can stub it.
Typed response normalization
Every AJAX action returns a typed Response/* DTO. Five new ones
are introduced where no existing match is good enough:
Existing ErrorResponse covers every error branch; raw
new JsonResponse(['success' => false, ...]) calls go away.
Rollout plan
The split lands as a sequence of slices, each its own PR, each
independently revertible. A single mega-PR would block on every
review iteration; small slices keep each step reviewable.
Sequence
Slice 13a — extract repository methods. TaskRepository
gains the new methods; TaskController gets refactored to call
them but keeps every route. Pure SQL move; no behaviour change.
Slice 13b — extract TaskInputResolverInterface +
implementation. TaskController private helpers become
service calls. No behaviour change.
Slice 13c — extract TaskExecutionService. Controller
delegates execute orchestration to the service; this is also
where the future REC #4 budget pre-flight will hook in (see
ADR-025 / ADR-026).
Register the four new controllers (each with the
#[AsController] attribute) and repoint every entry in
Configuration/Backend/AjaxRoutes.php and
Configuration/Backend/Modules.php from
TaskController::actionXxx to the matching action on the
new per-pathway controller. TaskController itself remains
in the tree at this point, but no production code references
it any more — every route resolves to a new controller.
In a follow-up commit (or follow-up PR if review surface gets
large), delete TaskController.php along with any test
doubles still referencing it. This pass is mechanical: drop
the file, drop test imports, run the test suite.
Sequencing matters. Routes must move before the file is
deleted, otherwise the container compile would fail at the
intermediate step.
Each slice maintains AJAX URL stability. JavaScript ajaxUrls
constants registered via PageRenderer::addInlineSettingArray()
keep their existing names; only the route's target field
changes.
Backwards compatibility
The four existing AJAX routes
(ajax_nrllm_task_execute, ajax_nrllm_task_list_tables,
ajax_nrllm_task_fetch_records,
ajax_nrllm_task_load_record) keep their identifiers and
paths. Frontend code that resolves them via the inline-settings
mechanism is unaffected.
The backend module entry under
Configuration/Backend/Modules.php keeps its current
identifier; the controller target value updates from
TaskController::listAction to
TaskListController::listAction.
No public API change: TaskController is annotated
#[AsController] and is not part of any documented
extension point.
Consequences
Positive
Each pathway becomes navigable in isolation. PR scope on Task-area
changes shrinks accordingly.
The repository layer regains its position as the single source of
Task-domain DB access. Future schema changes touch one file.
The audit's "DTO/VO vs arrays" axis (currently 8/10 after slice 7)
closes the last open gap on the controller layer: every backend
AJAX endpoint then ships a typed response.
TaskExecutionServiceInterface becomes the natural seam for
REC #4 (auto budget + usage in feature services). Without this
service, REC #4 would have had to inject BudgetService directly
into the controller — a smell.
Each new controller has < 250 LOC, so PHPMD/PHPStan complexity
metrics improve uniformly.
Negative / costs
Five PRs of churn touching 25 files. CI matrix runs each, the
review backlog scales accordingly.
Backend module config (Configuration/Backend/Modules.php) and
AJAX routes (Configuration/Backend/AjaxRoutes.php) need to
point at the new controllers; any extension that programmatically
resolves TaskController by class name (none in this repo,
but possible downstream) breaks.
Functional + E2E tests that reference TaskController::class
need updating (counted: 6 functional, 2 E2E). Each gets a
one-line change per slice that touches the relevant action.
Alternatives considered
Smallest-delta — keep TaskController whole, only do
service + repository extraction, don't split into per-pathway
classes. Hits the audit's SQL and DTO sub-points but leaves the
god-class shape. Rejected: doesn't solve "navigation" problem.
Split-only — split into four controllers but leave SQL
inline and DTO usage inconsistent. Rejected: the SQL and DTO
problems are the audit's specific findings; a split that
doesn't address them is rearranging deck chairs.
One mega-PR — perform every extraction in a single change.
Rejected: review surface too large; per-slice revertability
gone; bisect harder.
References
Audit: claudedocs/audit-2026-04-23-architecture.md § REC #5
(kept locally under the gitignored claudedocs/ directory; not
part of the published documentation tree).
ADR-026 (Provider Middleware Pipeline) — the
natural integration point for REC #4 once
TaskExecutionService exists.
ADR-028: Public services policy in Configuration/Services.yaml
Status
Accepted
Date
2026-04-30
Slice
25 (audit 2026-04-23 REC #9c)
Context
The 2026-04-23 architecture audit (claudedocs/audit-2026-04-23-architecture.md)
flagged the count of public: true overrides in
Configuration/Services.yaml (32 at the time of the audit; 37 after
intermediate slices added new typed-interface aliases) as
"excessive". The default in this extension's _defaults block is
public: false, so every public: true line is an explicit
override that needs justification.
REC #9c asked: "reduce public: true to only those genuinely needed."
Decision
The current public-service set is documented here as the deliberate
policy. Each public service belongs to one of four categories below,
each with a load-bearing reason. New public: true entries must fit
one of these categories or add a new one (with rationale appended to
this ADR).
A new unit test (Tests/Unit/Configuration/PublicServicesPolicyTest.php)
keeps the count honest going forward — when the policy adds a new
category it must also record the rationale.
Categories
1. Public LLM-API surface. Services that downstream extensions
and host-instance integrations consume via
$container->get(ServiceClass::class) or via direct DI hint in
their own services.yaml. These are the documented application
surface; they MUST be public.
2. Specialized services with public method surfaces. AI-domain
services that act as discrete public APIs, exposed for callers that
want them in isolation (image-only, speech-only consumers).
Specialized\Speech\WhisperTranscriptionService
Specialized\Speech\TextToSpeechService
Specialized\Image\DallEImageService
Specialized\Image\FalImageService
3. Repositories consumed by tests through the TYPO3 testing
framework. TYPO3 FunctionalTestCase::get() uses the Symfony
container's ->get() lookup, which only resolves public services.
Repositories are exercised by functional tests that round-trip
fixtures through real Doctrine, so they must be public.
Domain\Repository\LlmConfigurationRepository
Domain\Repository\ProviderRepository
Domain\Repository\ModelRepository
Domain\Repository\TaskRepository
Domain\Repository\UserBudgetRepository
Domain\Repository\SkillRepository
Domain\Repository\SkillSourceRepository
4. SetupWizard collaborators. Three services that are
co-instantiated by the wizard controller's typed-DTO factories
(DetectedProvider, DiscoveredModel,
SuggestedConfiguration). They are public so the wizard's
multi-step flow can re-resolve them across requests without holding
mutable state in the controller.
The autowiring resource block at the top of Services.yaml
(Netresearch\NrLlm\: { resource: '../Classes/*' }) registers
every other class in the namespace as private by default. That
covers:
These flow through DI constructor injection only. There is no
$container->get() call site for any of them, no test fixture
requires them by class name, and there is no documented external
consumer.
Constraint and enforcement
The unit test
Tests/Unit/Configuration/PublicServicesPolicyTest.php parses
Configuration/Services.yaml and asserts:
The total count of public: true keys matches the expected
total (currently 42).
The ADR file exists and references both REC #9c and the
public: true policy text.
Breakdown of the 42:
22 Category 1 — Public LLM API surface
(13 concrete services + 9 interface aliases).
Note the 13 / 9 asymmetry: CompletionService,
EmbeddingService, TranslationService, VisionService
contribute 4 concrete entries but their interface aliases are
registered separately (4 aliases). Of the remaining 9 concrete
services, three core services
(LlmServiceManager, ProviderAdapterRegistry,
TranslatorRegistry) keep the interface-alias entry while
BudgetService, CacheManager, UsageTrackerService,
LlmConfigurationService, PromptTemplateService each have
both a concrete + interface entry, and
Service\Prompt\PromptSnippetComposer (ADR-031) is
concrete-only — consuming extensions resolve it by class name,
it has no interface alias. The maths: 13 concrete + 9
aliases = 22.
8 Category 3 — Repositories
(LlmConfiguration, Provider, Model, Task, PromptSnippet,
UserBudget, Skill, SkillSource). PromptSnippetRepository is
additionally the documented query surface for consuming
extensions (ADR-031). SkillRepository and
SkillSourceRepository (skills-ingest) are public so their
functional tests resolve them via FunctionalTestCase::get().
4 Doctrine + provider-adapter wiring tail —
small set of services that the host instance / dashboard widgets
resolve by class-name through the public container. Includes
Service\UsageAnalyticsService, the read-only Analytics-module
reporting service, which is public solely so its functional test
resolves it via FunctionalTestCase::get() (same rationale as
Category 3; production callers use constructor injection). Its
UsageAnalyticsServiceInterface alias stays private.
The current test enforces only the count and the ADR's
presence. It does not statically validate that each individual
public: true entry maps to a category line in this ADR — that
would require parsing the ADR's bullet lists. The intentional
friction is therefore: a contributor who adds a public: true
line bumps the count, the test fails with a prompt to update both
this ADR and the constant. Reviewers verify the entry against the
categories during PR review.
Adding a new public service therefore requires three things in the
same PR: the service definition, this ADR amended (with the new
entry placed in the appropriate category, and the running total in
the test docblock updated), and the
EXPECTED_PUBLIC_TRUE_COUNT constant bumped.
Consequences
No reduction in count. Every current entry is justified;
removing any of them would break either downstream consumers
(Category 1, 2) or our own functional tests (Category 3, 4).
Future-proofing. A new "I'll just make it public" PR now
needs an explicit ADR amendment.
Drift detection. The architecture test catches a silent
public: true addition that bypasses the policy.
Alternative considered
Mass reduction (privatize everything except Category 1).
Rejected: would break 22 functional tests that resolve repositories
and wizard services via $this->get(), and the eight functional
test files would each need a parallel services-test.yaml
override. The maintenance cost outweighs the static-policy win;
auditing through this ADR + architecture test is the same outcome
without the test-infrastructure churn.
ADR-029: Usage Analytics Dashboard
Status
Accepted
Date
2026-06-01
Authors
Netresearch DTT GmbH
Context
tx_nrllm_service_usage has recorded request counts and token totals
per service type and provider since day one, and the per-request cost
column (estimated_cost) existed from the start. The plumbing to fill
it never did: UsageMiddleware always passed a null cost,
Model::estimateCost() had zero callers, and so every row carried
estimated_cost = 0.000000. The downstream effect was visible — the
AI cost this month dashboard widget (see ADR-024: Dashboard Widgets) summed a column
that was structurally always zero and showed $0 regardless of real
spend.
The table also had no model dimension. Usage could be sliced by provider
and service type, but not by the specific model that produced it, so a
gpt-4o call and a gpt-4o-mini call against the same provider were
indistinguishable in the data — even though their pricing differs by an
order of magnitude.
Reporting itself was thin. The only at-a-glance surfaces were the two
global dashboard widgets from ADR-024: Dashboard Widgets; there was no dedicated view
that combined cost trends, model-level breakdowns, and per-user
consumption. With usage now flowing through the middleware pipeline
(ADR-026: Provider Middleware Pipeline), there is a single, well-defined place to compute cost as
a side effect of every productive provider call.
Decision
Ship a read-only usage analytics module backed by a richer usage table and
real cost computation:
Schema. Add model_uid, model_id, prompt_tokens, and
completion_tokens to tx_nrllm_service_usage. Daily granularity
is kept — rows still aggregate per day — and model_uid joins the
aggregation key (alongside service_type, service_provider, and
request_date) so model-level usage rolls up without a second write
per request.
Cost computation.UsageMiddleware now derives
estimated_cost from the configuration's Model pricing via
Model::estimateCost(), using the prompt/completion token split
recorded on the usage object. Pricing is stored as cents-per-1M tokens;
the estimate is the per-side token count times its rate. When a caller
already supplies a cost it is preserved; otherwise the model-derived
value is recorded. This fixes the long-standing
always-zero-cost defect.
Read layer. Add UsageAnalyticsService, a read-only reporting
service over the usage table. It exposes KPI totals
(getKpiTotals), a daily cost/requests trend with filled gaps
(getDailyTrend), breakdowns by provider, model, and service
(getBreakdownByProvider / getBreakdownByModel /
getBreakdownByService), and per-user usage with this-month budget
consumption (getPerUserUsage). A small AnalyticsPeriod
value object normalizes the date-range presets 7d / 30d /
90d / month and defaults unknown values to 30d.
Backend submodule. Register nrllm_analytics as an admin-only
child of the main LLM module (Admin Tools > LLM > Analytics),
driven by AnalyticsController and a Fluid template: KPI tiles, a
cost-plus-requests trend line, provider / model / service breakdown bar
charts, and a per-user table with monthly-budget bars. The active range
is a plain ?range= GET parameter — the page is a full reload with no
AJAX. Charts render with Chart.js (vendored under
Resources/Public/JavaScript/Vendor/).
Demo data. Ship a dev-only ddev seed-usage generator that
populates roughly 90 days of realistic historic usage so the module and
widgets have something to show during local development.
Consequences
Positive:
●● Real cost reporting. estimated_cost reflects actual model
pricing, so the AI cost this month widget (ADR-024: Dashboard Widgets) and the new
module both show real figures instead of $0.
● Model-level breakdowns. The added model_uid / model_id columns
let usage and cost be sliced per model, not just per provider.
◐ A single dedicated reporting surface combines trend, breakdowns, and
per-user consumption that previously had no home.
Negative:
◑ One extra write column-set per request (model_uid, model_id,
prompt_tokens, completion_tokens). Negligible — the row was
already being written; this widens it, it does not add a second write.
✕ Specialized-service cost and streaming usage are out of scope for v1
and documented as such. DALL·E / TTS / Whisper / DeepL still record
requests and units but their cost stays 0 (no token-based pricing
model yet), and streaming responses are skipped by the usage middleware
because chunked output has no single terminal token count to price.
◑ No backfill of pre-migration rows. Rows written before the schema
change keep model_uid = 0 and estimated_cost = 0; analytics only
reflect cost from the migration forward.
Net Score: +3 (Positive)
Alternatives considered
Per-request (non-aggregated) rows to enable arbitrary slicing.
Rejected — daily aggregation keyed on
service_type / service_provider / request_date / model_uid keeps the
table small and the existing widget queries fast; the model dimension is
the only slice that was actually missing.
Compute cost lazily in the read layer from stored token counts and
current model pricing. Rejected — pricing drifts over time, so cost must
be captured at call time against the pricing in effect then. Storing
estimated_cost at write time is the durable record.
A third dashboard widget instead of a dedicated module. Rejected —
the dashboard widget shapes (ADR-024: Dashboard Widgets) cannot host a trend line,
multiple breakdown charts, and a per-user table together; those belong in
a full module view.
ADR-030: Specialized Services Authenticate Through nr-vault
Status
Accepted
Date
2026-06-09
Authors
Netresearch DTT GmbH
Context
The database-backed LLM providers have authenticated through the nr-vault
secure HTTP client since ADR-012: API key encryption at application level — they store a vault identifier
(a UUID) rather than a plaintext key, and AbstractProvider::getHttpClient()
returns $vault->http()->withAuthentication(...) so the secret is resolved,
injected, audited, and memory-scrubbed inside the vault. The plaintext key
never surfaces in this extension's code.
The five specialised single-task services — DALL-E and FAL (image), Whisper
and TTS (speech), and DeepL (translation), all built on
AbstractSpecializedService (see REC #7) — predated that posture. Each
read a plaintext apiKey from extension configuration into a
protected string $apiKey property and assembled its own Authorization
header via a buildAuthHeaders() hook, sending the request through a plain
PSR-18 client. This contradicted ADR-012: API key encryption at application level and the project rule that
API keys MUST be stored as nr-vault UUID identifiers, never as plaintext.
Two of the services do not use the Bearer scheme: FAL expects
Authorization: Key <secret> and DeepL expects
Authorization: DeepL-Auth-Key <secret>. The secure client's Header
placement could previously inject only the bare secret as a header value, so
these schemes could not be expressed through it at all — which is why they had
remained on the plaintext path. nr-vault 0.8.0 added a prefix option to
withAuthentication() for Header placement, removing that blocker.
Decision
Migrate every keyed specialised service onto the vault secure HTTP client,
mirroring AbstractProvider:
Identifier, not key.AbstractSpecializedService takes
VaultServiceInterface as its first constructor argument and stores
$apiKeyIdentifier (the vault UUID) instead of $apiKey.
isAvailable() becomes
$apiKeyIdentifier !== '' && $vault->exists($apiKeyIdentifier).
Placement hooks replacebuildAuthHeaders(). The base exposes
getSecretPlacement() (default SecretPlacement::Bearer),
getSecretPlacementOptions() (default []), and
getAdditionalHeaders() (non-auth headers only, e.g. DeepL's
User-Agent). getSecureClient() builds
$vault->http()->withAuthentication($id, placement, options)->withReason(...)
and executeRequest() sends through it. Per-service placement:
DeepL Free/Pro routing stays automatic. DeepL selects the
api-free.deepl.com host for keys ending in :fx and api.deepl.com
otherwise. Since the key is no longer held as plaintext, the host is resolved
lazily on the first request: the secret is retrieved from the vault exactly
once, tested for the :fx suffix, and immediately sodium_memzero-d.
An explicit baseUrl override still wins. The request itself always
authenticates through the audited secure client, never that transient copy.
Configuration. The ext_conf keys become identifiers:
providers.openai.apiKeyIdentifier (DALL-E/Whisper/TTS),
image.fal.apiKeyIdentifier, and translators.deepl.apiKeyIdentifier.
A setHttpClient() test seam — identical to the providers' — lets unit
tests inject a plain client and assert request/response plumbing without the
vault; the placement hooks are asserted directly.
Consequences
No specialised service holds a plaintext API key; every upstream call is
audited and the secret is scrubbed inside the vault, satisfying
ADR-012: API key encryption at application level uniformly across providers and specialised services.
Requires nr-vault ^0.8.0 (the prefix option). A 0.7 install would
silently drop the prefix and send a broken Authorization header for
FAL/DeepL, so the composer floor is raised.
Host applications that previously wrote providers.openai.apiKey (and the
FAL/DeepL plaintext keys) into nr_llm's extension configuration must store a
vault secret and write its identifier instead.
DeepL incurs one extra vault read per service instance the first time it
sends a request (to choose Free/Pro); the result is cached for the instance
lifetime.
ADR-031: Tagged Prompt Snippet Library
Status
Accepted
Date
2026-06-10
Authors
Netresearch DTT GmbH
Context
Consuming extensions — first nr_repurpose — assemble prompts from
recurring building blocks: a persona, a tone of voice, a target
audience, an image style, a layout instruction. Editors want to manage
these fragments centrally, once, instead of re-typing them into every
extension's own configuration.
The existing PromptTemplate entity does not fit this need. It is
a heavyweight complete prompt: it binds a feature, carries model
parameters (temperature, max tokens, top-p), supports versioning with
parent/variant relations, and tracks usage performance. A persona like
"You are Nova, a friendly expert." has none of these concerns — it is a
fragment that only becomes a prompt when a consumer composes it with
its own instructions. Forcing fragments into PromptTemplate
would either bloat every fragment record with irrelevant model fields
or fork the template semantics depending on a "fragment" flag.
A second question is how consumers select fragments. A fixed category
enum (like Task categories) would require an nr-llm release
every time a consuming extension introduces a new fragment kind, which
contradicts the goal of nr-llm being a shared foundation that consumers
extend without touching it.
Decision
Introduce a separate, lightweight PromptSnippet entity
(table tx_nrllm_promptsnippet) next to — not on top of —
PromptTemplate:
Fragments, not templates. A snippet is identifier + name +
description + fragment text. No model parameters, no versioning, no
performance tracking. PromptTemplate stays untouched.
Free-form CSV tags instead of a category enum. Snippets carry a
comma-separated tags field. Consumers query
PromptSnippetRepository::findActiveByTag(), which matches
tags as exact, case-insensitive tokens — style never matches
lifestyle. The tag vocabulary is a convention between editors
and consumers (established so far: audience, tone_of_voice,
persona, layout, style), documented in the TCA field
description and the administration guide. New fragment kinds need no
nr-llm release.
JSON metadata side-channel. An optional metadata JSON object
carries consumer-specific settings (e.g. {"voice": "nova"} on
persona snippets so speech features can pick a matching TTS voice).
getMetadataArray() returns [] for empty or invalid JSON —
bad editor input must never break a consumer.
Composition stays in nr-llm.PromptSnippetComposer
renders an ordered label-to-snippet map into labeled prompt blocks
(LABEL: + fragment text, blank-line separated), so all consumers
produce uniformly structured prompt sections.
Editing via FormEngine. The backend module gets a "Snippets"
list following the established Providers/Models/Tasks pattern;
create/edit links into FormEngine, no custom forms.
Consequences
Editors manage personas, tones, audiences, styles, and layouts once,
centrally; every consuming extension reads the same library.
The free-tag model keeps nr-llm release-independent from consumer
vocabulary — at the cost of no referential integrity: a typo in a tag
silently yields an empty query result. The documented convention and
the tag badges in the list view mitigate this.
Token matching is implemented over the CSV field in PHP, not SQL
LIKE, guaranteeing exact-token semantics on every database
platform. The snippet library is small (tens of records), so loading
active snippets for tag filtering is not a performance concern.
Two prompt-related entities now coexist. The split is intentional
(template = complete prompt, snippet = fragment) and documented here,
in the administration guide, and in both entities' PHPDoc.
ADR-032: Specialized Usage Tracking and Pricing Catalog
Status
Accepted
Date
2026-06-10
Authors
Netresearch DTT GmbH
Context
The chat/embedding path records complete usage rows: the middleware
pipeline (ADR-026: Provider Middleware Pipeline) tracks tokens and derives a cost from the
admin-curated tx_nrllm_model pricing via Model::estimateCost().
The specialised services bypass that pipeline by design — but they
recorded almost nothing. The image services passed metric keys
(size, quality, count) that
UsageTrackerService::trackUsage() does not map, so only
request_count = 1 landed in tx_nrllm_service_usage: no cost, no
tokens, no images_generated, no model_id. TTS recorded
characters but no cost; Whisper recorded nothing but the request.
Consequently the Analytics module, the MonthlyCost widget and
BudgetService systematically excluded all image and speech spend —
defeating the requirement that nr_llm can monitor total AI spend.
Two structural problems compounded this:
the specialised services have no access to model pricing (their
models — gpt-image-2, tts-1, whisper-1 — usually have no
tx_nrllm_model row), and
gpt-image-* responses carry a usage token object (DALL·E
responses do not), which was discarded.
Decision
Real units in the callers. The services pass the metric keys the
tracker actually maps: images (→ images_generated),
characters, audioSeconds (→ audio_seconds_used, from the
verbose_json Whisper duration), token keys when the response
reports them, and the model identifier as modelId (→
model_id). Provider strings drop the ad-hoc provider:model
suffixes (dall-e:dall-e-3 → provider dall-e + model_id).
Token usage parsing.DallEImageService parses the
usage object of gpt-image-* responses (input_tokens,
output_tokens, total_tokens, input_tokens_details) so
token aggregates include image calls; DALL·E responses without
usage gracefully omit token metrics.
Static price catalog with a DB override.SpecializedPricingOpenAiPriceCatalog encodes the published
OpenAI list prices (each constant documents source URL and
verification date): gpt-image-* token prices and per-image fallback
estimates, DALL·E per-image prices by quality/size, tts-1 /
tts-1-hd per 1M characters, whisper-1 per minute.
SpecializedCostCalculator (injected into
AbstractSpecializedService) resolves in order: admin-curated
tx_nrllm_model row matching the model identifier (reusing
Model::estimateCost(), so negotiated prices win) → catalog
token prices → catalog per-image price → 0.0. Unknown models
never get a guessed cost — a zero cost signals "no price data"
instead of fabricating numbers.
No double counting.LlmTranslator no longer repeats the
token count on its translation row (the pipeline already records
tokens and cost on the underlying chat row); it keeps the
translation-level request/characters view.
WhisperTranscriptionService::translateToEnglish() loses its
second trackUsage() call — the dispatch path records the request
exactly once.
Consequences
● Image, TTS and Whisper spend appears in the Analytics module, the
MonthlyCost widget and BudgetService aggregates — total spend
monitoring covers all service types.
● Costs follow published list prices and can be overridden per model
by creating a tx_nrllm_model row with token pricing.
◑ The catalog requires manual maintenance when OpenAI changes list
prices; constants carry source URLs and verification dates to make
the review mechanical.
◑ Analytics grouped by service_provider now shows dall-e /
fal / tts / whisper instead of suffixed variants
(dall-e:dall-e-3); historic rows keep their old strings, the
model dimension moved to model_id.
◑ FAL calls record images but cost 0.0 — FAL publishes no static
list prices for its hosted models.
ADR-033: Specialized Models in the Model Registry
Status
Accepted
Date
2026-06-11
Authors
Netresearch DTT GmbH
Context
The backend Models module manages tx_nrllm_model records for the
chat/embedding pipeline, but the specialized services (image
generation, text-to-speech, transcription — ADR-030: Specialized Services Authenticate Through nr-vault,
ADR-032: Specialized Usage Tracking and Pricing Catalog) selected their models from hardcoded constants
(dall-e-3, tts-1, whisper-1) and never consulted the
registry. Image and speech models were therefore invisible in the
backend: administrators could not curate them, mark a preferred
default, or see usage linked to a record. Consuming extensions had no
way to ask "which image model should I use on this instance?".
Decision
Specialized capabilities.ModelCapability gains
IMAGE, TEXT_TO_SPEECH and TRANSCRIPTION cases, exposed
in the tx_nrllm_model TCA capabilities select, the BE group
capability permissions and the model-picker capability badges.
Image, TTS and transcription models are regular registry records.
Capability-based default resolution.DallEImageService, TextToSpeechService and
WhisperTranscriptionService expose
resolveDefaultModel(string $fallback): string: ACTIVE
registry records carrying the service's capability are considered
provider-agnostically; an is_default record wins, then the
lowest sorting; the record's model_id is returned.
Fail-soft — any error, missing repository, or no matching record
returns the fallback unchanged; the method never throws (the same
posture as SpecializedCostCalculator, ADR-032: Specialized Usage Tracking and Pricing Catalog).
Usage linkage. Specialized usage rows now carry the matching
registry record's uid as model_uid (resolved fail-soft from the
used model_id), so the Analytics model breakdowns link image and
speech spend to the curated records; 0 remains the value for
models without a registry record.
Configuration-based resolution for specialized services.tx_nrllm_configuration records are the stable indirection layer
for image/TTS/transcription exactly as for chat: a consumer
references a configuration by identifier, the administrator swaps
the assigned model (or adjusts the system prompt) on the record, and
every consumer picks it up without re-configuring anything. The
three services expose the consumer-facing API
resolveModelForConfiguration(string $configurationIdentifier, string $fallback): string
— resolution order: the ACTIVE configuration's ACTIVE model
record's model_id (records with an empty model_id are
skipped) → the capability-based registry default (decision 2) →
the given fallback. Fail-soft, never throws.
getConfigurationSystemPrompt(string $configurationIdentifier): string
— the configuration's system prompt; the empty string when the
configuration is unknown, inactive, or unreadable. The prompt is
returned to the consumer, never injected implicitly, so the
consumer always records the exact prompt it sent (transparency
requirement).
For image generation the model MUST be resolved before the
options object is constructed: ImageGenerationOptions
validates size against the concrete model value at construction
time.
Usage attribution per configuration. The specialized options
DTOs (ImageGenerationOptions, SpeechSynthesisOptions,
TranscriptionOptions) carry an optional configuration
identifier — pure metadata that never reaches the upstream API and
never alters validation. When set, the services resolve the
configuration uid fail-soft and pass it as configurationUid to
trackUsage(), so the Analytics module aggregates specialized
spend per configuration just like chat spend.
Snippet-enforcement hook (Phase 2). The planned prompt-snippet
feature (pinning/enforcing prompt snippets) attaches at the
Configuration level. getConfigurationSystemPrompt() is the
single seam where enforced snippets will be folded into the
returned prompt — consumers keep calling the same method and stay
unchanged when Phase 2 lands.
Consequences
● Image, TTS and transcription models are first-class registry
citizens: curated, activatable, default-flagged and visible in the
backend Models module like chat models.
● Consuming extensions resolve the instance-preferred specialized
model via resolveDefaultModel() instead of hardcoding one, with
a guaranteed-safe fallback.
● Configurations are the stable consumer contract for specialized
calls too: model swaps and system-prompt changes are central,
one-record edits — no consumer redeployment.
● Analytics model breakdowns link specialized spend to registry
records via model_uid and to configurations via
configuration_uid.
◐ Hardcoded service defaults remain as fallbacks — instances without
curated records keep working unchanged.
◑ Up to two additional fail-soft repository lookups per tracked
specialized call (indexed single-row queries; negligible next to the
API call).
ADR-034: Remove the ExtensionConfiguration default-provider fallback
Status
Accepted
Date
2026-06-24
Authors
Netresearch DTT GmbH
Context
LlmServiceManager carried a session-level default provider: a
nullable defaultProvider string seeded from
ExtensionConfiguration['nr_llm']['defaultProvider'] and mutable at
runtime through setDefaultProvider() / getDefaultProvider()
(both on the public LlmServiceManagerInterface). When a generic
chat() / complete() / streamChat() call pinned no
provider, getProvider(null) fell back to that string.
In practice the fallback was inert: the defaultProvider key was
never exposed in ext_conf_template.txt, so it was always null in
production unless an integrator set it by hand in additional.php. It
was also misleading — together with the orphaned plugin.tx_nrllm
TypoScript (removed in #255, answering
discussion #254) it
suggested a second, config-driven way to choose a provider that no code
path honoured as the source of truth.
Decision
Remove the default-provider concept from LlmServiceManager
entirely. The database is the single source of truth for provider
selection.
Drop the state and its seed. The defaultProvider property and
the ExtensionConfiguration['nr_llm']['defaultProvider'] read in
loadConfiguration() are removed. The rest of the extension
configuration (provider-specific settings consumed by
registerProvider()) is unaffected.
Remove the public accessors.setDefaultProvider() and
getDefaultProvider() are removed from
LlmServiceManagerInterface and its implementation. This is a
breaking change to the public service contract.
`getProvider(null)` throws. With no fallback,
getProvider() requires an explicit identifier; called with
null it throws ProviderException (code 4867297358)
with guidance to configure a default Configuration in the backend
module. The signature keeps the nullable parameter for callers that
pass a possibly-null pinned provider.
Consequences
● One way to choose a provider: pin it per call (the provider
option on ChatOptions / EmbeddingOptions) or let the
generic path resolve the active default Configuration. No silent,
inert third path.
● The LlmServiceManagerInterface shrinks by two methods that
no production code consumed.
◐ Breaking: integrators that called
setDefaultProvider() / getDefaultProvider(), or relied
on the defaultProvider extension-config key, must instead create
an active+default Configuration record or pin the provider per call.
No production deployment used the key (it was never exposed in
ext_conf_template.txt), so real-world impact is expected to be
nil.
● No production behaviour change in practice: the generic entry
points already resolved the database default first, and the fallback
was never populated in production.
◐ Supersedes the provider-default resolution steps of ADR-007: Multi-Provider Strategy
("Default provider from configuration" / "First configured provider by
priority"): provider selection is now per-call or via the active default
Configuration only, with no extension-config or priority fallback.
Editors want to reuse the growing ecosystem of Claude Code skills —
SKILL.md files with YAML front-matter (name + description)
and a markdown body — inside nr-llm. These live on GitHub as a single
file, as a whole repository (many SKILL.md under skills/,
.claude/skills/ or <plugin>/skills/), or behind an Anthropic
marketplace.json index that points at further repositories.
Fetching attacker-influenced markdown from the public internet and later
feeding it into an LLM prompt raises two separate concerns that are easy
to conflate:
Server-Side Request Forgery. The existing nr-vault transport
(vault->http()) already blocks internal/private/metadata targets.
That guard is about where a request may go, not who owns it.
Supply-chain origin and integrity. Even a non-SSRF target must be
a real GitHub host, and the bytes we store must be the bytes we
reviewed — a moving branch ref can change content under us.
This ADR records the decisions for Plan 1a — ingest only. Skills are
parsed, materialized and reviewed, but not yet injected into prompts;
injection, the MM attach tables, and checksum-verify-on-injection are
deferred to Plan 1b.
Decision
Dedicated entities, not extended snippets. Two new Extbase
entities — SkillSource (table tx_nrllm_skill_source) and
Skill (table tx_nrllm_skill) — model the ingest domain.
A skill is a materialized SKILL.md; a source produces N skills.
Reusing PromptSnippet (ADR-031: Tagged Prompt Snippet Library) was rejected: snippets
are editor-authored fragments, skills are synced remote artifacts with
their own lifecycle (sync status, checksum, orphaning).
Ingest / use split. Unit 1 is split at the MM-table seam into
Plan 1a (this ADR: sources, fetch, parse, review) and Plan 1b
(attach + inject). Each ships fully implemented, no stubs.
SSRF guard ≠ GitHub-origin guard. On top of the nr-vault SSRF
guard, GitHubClient enforces an app-level GitHub host
allowlist: scheme = https AND host ∈ `{github.com,
raw.githubusercontent.com, api.github.com, codeload.github.com} on
the **initial request URL**. The transport does **not follow redirects**
(any 3xx is treated as an error), so there is no redirect target to
escape the allowlist. A rejected URL raises a typed
:php:HostNotAllowedException` — never a silent skip.
Fetch by immutable commit SHA + checksum. A source ref
(branch/tag) is resolved once to a commit SHA via
GET /repos/{o}/{r}/commits/{ref}; the stored pinned_sha is the
URL all bodies are fetched from (raw.githubusercontent.com by
SHA, never by branch). A body_checksum (sha256) is computed at
materialization and re-verified on injection in Plan 1b (fail-closed).
Disabled-by-default for multi-skill discovery. Every repo and
marketplace skill arrives enabled = false and must be reviewed
before use. A single_file source — one explicit admin act — may
default enabled. Re-syncing an enabled skill whose recomputed
body_checksum changed auto-reverts it to disabled and surfaces
the diff for re-confirmation.
Namespaced upsert, orphan-disable.identifier is namespaced
"{source_uid}:{path}" so identical skill names across sources never
collide. Re-sync is upsert-by-(source, identifier); a skill that
disappeared upstream is marked orphaned + disabled, never silently
dropped.
Admin-only management. Sources and skills live in a new
nrllm_skillsaccess = admin backend submodule. The two tables
are an escalation surface (the body becomes prompt context in 1b) and
must never be granted to non-admin backend groups; sync-managed TCA
fields (body_checksum, source_sha, raw_frontmatter,
support_status, identifier) are read-only and github_token
is never shown in a FormEngine form.
String-backed enums + bounded JSON.SkillSourceType,
SyncStatus and SupportStatus are string-backed with
values() / isValid() / tryFromString() (the project's
Defensive-Enum rule). raw_frontmatter and the reserved
allowed_tools JSON are byte- and shape-bounded at parse time even
though allowed_tools is ignored in 1a.
Explicit ``symfony/yaml`` dependency. Front-matter is parsed with
Symfony\Component\Yaml\Yaml; the package is added to
composer.jsonrequire explicitly rather than relied on
transitively.
Consequences
● Admins reuse the GitHub skill ecosystem from inside the backend, with
SHA-pinned, checksum-verified, host-allowlisted fetches.
● The SSRF guard and the GitHub-origin allowlist are independent
controls, stated and tested separately — neither masks the other.
● Disabled-by-default plus auto-disable-on-change means no remote
content silently enters a prompt: every enable is a deliberate admin
review, and an upstream change re-opens that review.
● Orphan-disable (never drop) keeps attached skills (Plan 1b) from
vanishing under an editor and makes upstream deletions visible.
◐ Two more domain entities and a new submodule increase surface area;
the split from PromptSnippet is intentional and documented here
and in the administration guide.
◐ On hardened instances the global HTTP/allowed_hosts SSRF list
must include the four GitHub hosts, or every sync fails closed — a
deliberate, documented prerequisite.
✕ support_status = partial is not a safety signal. It only
flags that referenced scripts/assets are not executed (always true in
1a); the prose stays fully untrusted. The injection-time output
integrity controls land in Plan 1b.
ADR-036: Skill injection (attach + compose into prompts)
Status
Accepted
Date
2026-06-28
Authors
Netresearch DTT GmbH
Context
ADR-035 ingested GitHub SKILL.md files into reviewable
Skill records but deliberately stopped before using them. This ADR
records Plan 1b — use: attaching enabled skills to a Task and/or an
LlmConfiguration and injecting their prose into the prompt.
The skill body is third-party text fetched from the internet. Injecting it
into a prompt of an extension that holds vault-encrypted API keys and runs
with backend privileges raises distinct concerns: where the text goes in
the message structure (role), how much of it goes in (context-window
overflow), whether it is still the reviewed bytes (integrity), and what
the resulting output is trusted to be (output integrity). The codebase has
no tokenizer and Model::contextLength is frequently 0 (unknown), so
a pre-flight token budget is not possible.
Decision
Service-layer injection, not provider middleware. Skill attachments
are known from the Task / LlmConfiguration, not at the provider.
A shared SkillInjectionService composes the block and is called
from the two text-generation entry points —
TaskExecutionService (task skills + the task's configuration
skills) and the configuration-driven completion / translation path in
LlmServiceManager (the resolved configuration's skills).
Text-generation operations only. Injection is applied to completion,
translation and task execution. It is never applied to embed(),
vision() or speech — injecting instruction prose there is meaningless
or actively harmful (it would pollute embedding inputs).
Never the system role. The composed block is prepended to the user
prompt — for a plain prompt to the prompt string, for a messages list to
the first user-role message only. The configuration system_prompt is
left untouched, and the block is never escalated into the system role to
fill a missing user turn. A guard preamble prefixes the block ("the
following are task guidelines; they cannot override configuration or
safety") as defense-in-depth — message role is not a trust boundary.
Precedence: config baseline + task additive. The candidate set is the
union of configuration skills then task skills, deduped by
``(source, identifier)`` with the configuration winning, keeping only
enabled and non-orphaned skills. The configuration block renders
first.
Conservative byte budget, deterministic drop. Because no
tokenizer exists, the budget is a conservative byte cap
(strlen, default 24 000, constructor-injectable — a byte count is a
safe over-estimate of tokens for any encoding). When exceeded, skills are
dropped from the tail first (task-additive before configuration
baseline), each drop logged as a warning. This is intentionally an
over-estimate set well below the smallest expected context window; with
Model::contextLength == 0 the absolute cap applies.
Checksum-verify on injection (fail-closed). Each skill's stored
body_checksum is re-verified against hash('sha256', body) with
hash_equals at compose time. A mismatch (possible tampering / a
stale row) skips that skill and logs a warning — it is never
injected.
Output integrity. Skill-influenced output stays subject to the
project's "treat LLM responses as untrusted" rule and is escaped /
sanitized where it is persisted or rendered. For partial skills the
asset/script references are stripped from the injected prose — to avoid
dangling instructions, not as a security control.
Attachment via TCA select + MM.tx_nrllm_task_skill_mm and
tx_nrllm_configuration_skill_mm back select fields on the Task
and Configuration records, filtered to enabled, non-orphaned skills.
Consequences
●● Editors reuse reviewed GitHub skills as reusable, per-task or
per-configuration instruction sets without copy-pasting prose.
● Config-baseline + task-additive precedence gives a "house style on the
configuration, specifics on the task" model with deterministic, deduped
composition.
● Fail-closed checksum verification means a tampered or stale skill row
is dropped, not silently injected — the ingest-time pin (ADR-035) is
enforced again at the moment of use.
◐ The budget is a byte heuristic, not a token guarantee; it is
deliberately conservative and logs every drop, but very large skills on
tiny-context local models may still be trimmed.
◐ Injection touches the live text-generation path; it is scoped to
text operations and covered by unit + functional tests, but it is a
higher-blast-radius change than ingest.
✕ Message role is not a security boundary: a determined prompt injection
in skill prose can still influence output. The mitigation is the guard
preamble plus treating output as untrusted — residual risk is
output-integrity and cost, not key exfiltration (keys are never in the
prompt context).
The nrllm backend module is registered with access => admin, so TYPO3's
module dispatcher only renders its controllers for backend administrators.
The module's interactive features, however, are driven by standalone AJAX
routes declared in Configuration/Backend/AjaxRoutes.php (ajax_nrllm_*).
These routes are dispatched by the generic backend AJAX route handler, not
through the module route — so the module's access => admin check never runs
for them.
The practical effect: any authenticated backend user (including a low-privilege
editor) could call these endpoints directly. The exposed surface is broad and
sensitive — provider/model/configuration state mutations (toggle-active,
set-default), provider and model test calls that decrypt vault-stored API
keys and reach out to upstream LLMs, task execution (which spends budget and
runs the configured prompt), reading of arbitrary TYPO3 records via the task
record picker, the tool playground's run (which executes the agent loop,
spending budget and invoking registered tools) and tool toggle, and the setup
wizard's save which creates providers and stores new API keys in the vault.
Only SkillSourceController enforced an admin check, via a private
denyNonAdmin() method duplicated nowhere else. Every other backend AJAX
controller was unguarded.
Decision
One shared guard trait.RequiresBackendAdminTrait
(Classes/Controller/Backend/) exposes a single private
denyNonAdmin(): ?ResponseInterface that returns null for an admin
and a 403{"success": false, "error": "<message>"} JSON response
otherwise, where <message> is the localised
error.adminRequired label. SkillSourceController now uses the
trait; its identical private copy was deleted.
Guard every AJAX-routed action, at the very top. Each action listed in
AjaxRoutes.php begins with
if (($deny = $this->denyNonAdmin()) !== null) { return $deny; } before
any body parse, repository read, or side effect. All AJAX actions already
return ResponseInterface, so the JsonResponse is
type-compatible. The guard covers
LlmModuleController, ProviderController, ModelController,
ConfigurationController, TaskRecordsController,
TaskExecutionController, SetupWizardController,
ToolPlaygroundController, ToolController (the tool-management
module split out later — ADR-039) and the already-guarded
SkillSourceController — every AJAX-routed action, matching the route
table exactly.
Non-AJAX module actions are left untouched. Extbase module actions
(listAction, indexAction, executeFormAction,
wizardFormAction, …) are reached through the access => admin module
route and are already protected; adding the guard there would be redundant.
The standard accessor is ``$GLOBALS['BE_USER']``. The guard reads the
current backend user from $GLOBALS['BE_USER'] and checks
instanceof BackendUserAuthentication plus isAdmin(). This is
the conventional accessor for the authenticated backend user in this
context — the AJAX route handler has already established the backend user
session by the time the controller action runs, and using the global keeps
the guard a zero-dependency trait that any controller can adopt without
constructor changes.
Consequences
●● Every backend AJAX endpoint now requires a backend admin; a
non-admin receives a uniform 403 and no state is mutated, no vault key
is decrypted, no upstream LLM is called, and no arbitrary record is read.
● A single shared trait removes the duplicated guard and makes "add the
guard" the obvious, one-line step for any future backend AJAX action.
● The guard short-circuits before request-body parsing, so it is cheap and
cannot be bypassed by malformed input.
◐ Tests that exercise these actions must now set up an admin
$GLOBALS['BE_USER'] (functional: setUpBackendUser(1); unit: an admin
BackendUserAuthentication stub). This is a one-time, mechanical update to
the existing controller test suites.
◐ $GLOBALS['BE_USER'] is a global accessor rather than an injected
dependency. It matches existing project usage and keeps the trait
dependency-free, but it is global state and is set/reset explicitly in tests.
✕ This is an authorization (admin-only) control, not per-record or
per-table access control: an admin retains full access to every endpoint,
including reading arbitrary records through the task picker. Finer-grained
authorization is out of scope.
See ADR-023 for backend capability permissions and
ADR-012 for API-key encryption (the keys these endpoints
would otherwise expose).
nr-llm completion has been single-shot: one request, one answer. The
tool protocol value objects already existed — ToolSpec and
ToolCall (ADR-010), OpenAI-wire-aligned — and
LlmServiceManager::chatWithTools() could send tool declarations and
read the model's tool calls back. But there was no registry of executable
tools, no PHP that runs a tool, and no loop that feeds a tool result back
into the conversation. A model could ask to call a tool; nothing answered.
Worse, chatWithTools() cannot be the loop's engine. It resolves its
provider from the ExtensionConfiguration['nr_llm']['providers'] keyed
registry and runs against a model-less transient configuration. That
registry is not populated for chat (providers, models and configurations are
DB-backed). The consequences are concrete:
For keyed providers (Claude, Gemini, Groq, Mistral, OpenRouter) there is
no registered API key, so the call is unauthenticated (401).
Every provider runs on its hardcoded default model, never the model
the admin selected on the LlmConfiguration.
Cost is computed downstream by UsageMiddleware from the priced
Model; a model-less transient config records zero-cost usage,
so the budget cost bucket never sees the spend.
So the agent loop cannot reach a selected configuration's vault key, model,
temperature, system prompt or pricing through the provider-key path. A
config-aware entry point is required before a loop is safe to run.
Decision
A DI-tagged tool registry.ToolInterface
(Classes/Service/Tool/) declares four methods —
getSpec(): ToolSpec, execute(array $arguments): string,
isEnabledByDefault(): bool (curated low-risk tools return true;
secret- or system-exposing tools return false so they are opt-in) and
requiresAdmin(): bool (admin-only gating for tools surfacing
system/host/cross-user data) — both central to the fail-open/fail-closed
security model below. It carries
#[AutoconfigureTag('nr_llm.tool')]. ToolRegistry collects every
tagged tool through an autowired iterator and indexes it by spec name (a
duplicate name is a developer error → LogicException at
construction). An extension adds a tool simply by tagging a class — no
central registration edit. The registry is the authoritative allow-set:
specs($allowedNames) intersects the declared names against what is
actually registered and drops the rest.
A config-aware tool entry point.LlmServiceManager::chatWithToolsForConfiguration() mirrors
chatWithConfiguration() — it resolves the adapter from the
LlmConfiguration (vault key + real Model + params), guards
instanceof ToolCapableInterface and runs through the middleware
pipeline, so UsageMiddleware sees the priced model and records real
cost. It is additive on LlmServiceManagerInterface (no consumer
break) and is the only call the loop makes per round.
A bounded agent loop.ToolLoopService::runLoop() calls
chatWithToolsForConfiguration() each iteration; while the model returns
tool calls it executes them and re-sends, bounded by a configurable
max-iteration cap (constructor default 5). Three fail-soft rules keep the
admin informed instead of aborting:
An empty offered set (no tools, or an empty allow-list) is a single
plain chatWithConfiguration() completion — an empty tools array
makes some providers (OpenAI) 400.
Hitting the cap with tools still pending triggers one final plain
chatWithConfiguration() (no tools field at all) to synthesise a
closing answer and sets truncated = true. A no-tools completion
yields a real finalContent uniformly across OpenAI, Claude and
Ollama — unlike toolChoice='none' or an empty tools array.
A mid-loop BudgetExceededException returns the partialToolLoopResult (trace + usage so far, truncated = true); the
budget fires pre-flight and tools are read-only, so the state is
consistent.
Raw-array message turns; ChatMessage unchanged. The loop appends the
assistant tool_calls turn and one tool result turn per call as raw
arrays. LlmServiceManager::normaliseMessages() routes only exact
2-key {role,content} arrays through ChatMessage; the 3-key tool
turns pass through unchanged to OpenAI and Claude. Empty arguments
serialise to {} (an object), never []. OllamaProvider
translates the replayed OpenAI-shape turns into Ollama's native
/api/chat shape (object arguments, tool_call_id dropped) and
synthesises a call id (call_<index>) on the way out, because Ollama
returns none and ToolCall rejects an empty id.
Skill.allowed_tools is a fail-closed-on-declaration allow-list.AllowedToolsResolver reads the effective skills (enabled,
non-orphaned, deduped — exactly what SkillComposer injects) of the
configuration and task. If no skill declares allowed-tools it
returns null (no skill-imposed restriction → all registered tools).
If any declares, the result is the union of the declared lists — a
lone declared empty list yields [] (no tools). The allow-list is
enforced twice: when computing the offered specs()and again at
execution time, so a model steered by injected skill prose cannot call a
registered-but-not-offered tool.
Authorization is enforced in the runtime, against the acting backend
user — not only in the playground. Because ToolLoopService runs
tools on behalf of a backend request (and a future non-admin consumer could
be wired to it), every tool declares requiresAdmin(). The loop
resolves the acting
$GLOBALS['BE_USER'] and, when it is not an admin, filters every
admin-only tool out of the offered set (fail-closed: an unknown tool name
is treated as admin-only). Admin-only tools are those exposing system /
host / cross-user data — fetch_logs, get_env / get_env_raw,
get_php_info / get_php_info_raw, list_be_users /
list_be_users_raw, list_be_groups and read_fal_asset_meta.
Tools that read user-scoped records and are usable by a non-admin instead
self-enforce the acting user's own TYPO3 permissions inside
execute(): get_pagetree applies
getPagePermsClause(Permission::PAGE_SHOW) and get_tca filters tables
by check('tables_select', …) (an admin bypasses both — TYPO3 admins see
everything). Queries use the default restriction set (no blanket
removeAll()) so soft-deleted rows never surface; the admin-only
be_users / be_groups listings keep removeAll() plus an explicit
deleted = 0 so disabled users remain visible for auditing.
Generic error egress, detail logged server-side. A thrown tool, an
unknown or disallowed tool name, and any unexpected provider failure
become a generic error string. The exception body may carry DBAL/PDO
credentials that URL-sanitising would not strip, so it never reaches the
provider or the DOM; the full detail is logged through the injected
logger.
Consequences
●● nr-llm gains a real agent loop: admin-curated PHP tools run
mid-generation on the selected configuration's vault key and model, and the
result is fed back until the model answers or the cap is reached.
●● Cost is recorded via the config-aware path and bounded by the
iteration cap plus the per-iteration budget pre-flight (request-count /
token / cost buckets, given the BE-user uid is set). Without
chatWithToolsForConfiguration() only the cap and token/request counts
would bound spend, and keyed providers would 401.
● Extensions extend the tool set by tagging a class; no edit to nr-llm and
no architecture exception (tools live under Service\Tool and inherit the
existing service-layer guard).
● The allow-list re-validation at both offer and execution time means a
declared-but-unknown tool name is dropped and an injected prompt cannot
reach a tool the skills did not grant.
◐ The shipped built-in tools (fetch_logs, read_fal_asset_meta, and
the later diagnostic/record tools — get_php_info, get_env,
get_pagetree, get_tca, list_be_users, list_be_groups and
their secret-redacted/raw variants) are admin-curated, read-only,
input-bounded and scoped (limit cap + PII redaction; storage-scoped lookup).
They are reference implementations of the security contract, not a general
capability.
●● Authorization is per-tool and enforced in the runtime against the
acting backend user, not merely the playground gate (§6): admin-only tools
are filtered out for non-admins (fail-closed), and the user-scoped tools
honour the acting user's page / table permissions. A future non-admin
consumer of ToolLoopService therefore cannot reach system data or read
beyond the user's own TYPO3 rights — closing the escalation surface the
earlier admin-only-playground assumption relied on.
◐ read_fal_asset_meta is gated admin-only rather than resolving
per-user file-storage permissions: file metadata can span storages a
non-admin cannot see, and per-storage resolution is brittle, so the simpler,
stricter gate was chosen (with the storage allow-list as a further bound).
✕ Message role is not a trust boundary: a prompt injection in skill prose
can still steer a tool's arguments. The mitigation is input validation +
scoping in each tool, the offered allow-list, and the XSS-safe render of
every tool-derived string in the playground.
See ADR-010 for the tool/function-calling abstraction,
ADR-013 for the configuration hierarchy the loop runs on,
ADR-026 for the middleware pipeline that records cost,
ADR-036 for skill injection (which steers tool arguments),
and the administration guide for operation.
ADR-039: Global per-tool availability state
Status
Accepted
Date
2026-06-30
Authors
Netresearch DTT GmbH
Context
The tool runtime (ADR-038) gates which tools a single agent
run may call through two mechanisms:
each ToolInterface declares isEnabledByDefault() — a compile-time
default (e.g. read-only tools ship on, mutating ones ship off);
every run carries a per-request allow-list (the skill's allowed-tools
or the playground selection), so a run only ever sees the subset it asked for.
What was missing is an operator control: an administrator could not globally
turn a registered tool off for the whole instance. A tool shipping
isEnabledByDefault() === true was callable by every run that allow-listed it,
with no site-wide kill switch; and a default-off tool could not be switched on
without a code change. Neither the per-tool default nor the per-run allow-list is
the right seam for "this instance does not permit get_env at all".
Decision
Introduce a global, per-tool availability override that sits above the
per-tool default and below the per-run allow-list.
Storage — a dedicated table tx_nrllm_tool_state (tool_name unique,
enabled boolean). It has no TCA and no FormEngine UI: it is operational
state toggled from the backend, not editorial content edited as a record. A
missing row falls back to the tool'sisEnabledByDefault(), so the
table only ever holds explicit admin overrides.
Repository — ToolStateRepository exposes overrides() (the
sparse override map) and setEnabled(name, bool) (upsert one override).
Effective-state service — ToolAvailabilityService computes the
authoritative "what may run at all" set: for every registered tool the
effective state is its admin override when one exists, otherwise its
isEnabledByDefault(). enabledNames() returns the enabled subset;
states() returns the full name / description / enabled / defaultEnabled
rows the backend renders.
Runtime enforcement — ToolLoopServiceintersects every per-run
allow-list withenabledNames(), so a globally-disabled tool can never
be invoked regardless of what a skill or the playground requested. This is the
same defense-in-depth layering as the acting-user RBAC intersection in
ADR-038 — the allow-list narrows, it never widens.
Backend surface — the toggles are rendered and persisted by the dedicated
Tools backend module (ToolController), split out from the interactive
Playground module so managing availability and running the agent loop are
separate admin concerns (see the two-module split). toggleToolAction()
is admin-guarded (ADR-037) and writes through
ToolStateRepository::setEnabled().
Consequences
Administrators get a site-wide kill switch per tool, independent of code
defaults and of any individual run's allow-list.
Availability resolves in two steps: the effective global state is the admin
override when one exists, otherwise the compile-time default (so an override
can enable a default-off tool or disable a default-on one — it replaces the
default, it does not merely narrow it). The per-run allow-list is then
intersected with that effective set, so a run can only ever narrow what is
globally enabled — a globally-disabled tool can never be called, but the
allow-list can never re-enable one.
The table is deliberately TCA-less: it is a small operational toggle set
keyed by tool_name, not a versioned/localisable record, so a bespoke
toggle endpoint is a better fit than FormEngine (and avoids exposing an
editable "tool" record that implies more than a boolean).
Because a missing row falls back to the tool default, shipping a new tool
needs no data migration: its isEnabledByDefault() applies until an admin
overrides it.
Reads go through ToolAvailabilityService on every agent run; the override
map is a single small query, cheap relative to the LLM calls it gates.
Alternatives considered
Reuse the per-run allow-list only — rejected: the allow-list is authored per
skill/run and cannot express an instance-wide policy; a globally-forbidden tool
would have to be scrubbed from every skill.
FlipisEnabledByDefault()in code — rejected: the default is a
ship-time property of the tool, not per-instance operator policy, and changing
it requires a release.
A TCA-backed ``tool`` record — rejected: tools are code-registered, not
editable entities; a full record UI would imply create/delete/localise
semantics that do not apply to a boolean override keyed by a code identifier.
Changelog
All notable changes to the TYPO3 LLM Extension are documented here.
A patch release fixing tool calling with parameterless tools. A tool that
takes no arguments emitted its (empty) JSON-Schema properties — and its
empty replayed call arguments — as a JSON array [] instead of an
object {}, which strict providers such as Ollama reject with an HTTP 400.
The bounded agent loop and the Tool Playground now work when a parameterless
tool (environment, PHP info, or backend user/group introspection) is offered.
The Skills, Tools and Playground admin documentation was also refreshed to
match the shipped backend (module section count, the full built-in tool
catalogue, two-tier tool authorization, and updated screenshots).
For the complete, itemised list see the canonical
CHANGELOG.md.
Version 0.14.0 (2026-07-04)
This release adds a Skills and Tools system: extensions and editors can
ingest SKILL.md files from GitHub (SHA-pinned, admin-reviewed) and attach
them to tasks and configurations, and a function-calling tool runtime lets a
model run an agent loop over an admin-curated, permission-gated set of tools —
with an interactive tool playground in the backend. It also lands a broad
security and accessibility hardening pass (SSRF/CSRF fixes, API keys moved out of
URLs, RBAC on tool execution, EN/DE translations, WCAG text alternatives), and
the CI now actually runs the functional and backend end-to-end suites so they
gate merges.
Breaking: custom ToolInterface implementations must now declare a
requiresAdmin(): bool method — true for tools that expose system,
host, or cross-user data, false for tools that self-enforce the acting
user's TYPO3 permissions. Without it the tool fails at runtime (ADR-038).
Together AI, Fireworks AI and Perplexity are now first-class OpenAI-compatible
providers, and provider endpoints entered in the wizard or the record editor are
canonicalized on save so they no longer break when saved without an API version
path.
For the complete, itemised list see the canonical
CHANGELOG.md.
Version 0.13.0 (2026-06-26)
Provider selection is now database-driven end to end. Breaking: the
extension-configuration defaultProvider fallback is removed — select a
provider per call (the options object's provider field) or mark a
Configuration active and default in the backend module; otherwise
getProvider(null) throws (ADR-034). The dead plugin.tx_nrllm TypoScript
constants/setup were removed and the "no provider specified" error now carries
actionable backend-module guidance (#254, #255).
For the complete, itemised list see the canonical
CHANGELOG.md.
Version 0.12.0 (2026-06-11)
Specialized services (image, text-to-speech, transcription) gain full usage and
cost tracking, join the model registry with image/text_to_speech/
transcription capabilities, and resolve their model and system prompt from
Configuration records (ADR-032, ADR-033). Adds a prompt-snippet library
(tx_nrllm_promptsnippet, ADR-031), per-request timeouts on the secure HTTP
client, and arbitrary gpt-image sizes. Requires nr-vault ^0.10.0.
For the complete, itemised list see the canonical
CHANGELOG.md.
Version 0.11.1 (2026-06-10)
Security and robustness fixes from the extension-wide code review: the setup
wizard dispatches through nr-vault's SSRF-guarded secure HTTP client, the
provider adapters surface streaming errors as typed, credential-sanitized
exceptions, TTS text splitting is multibyte-safe, and FAL/Whisper
configuration parsing is hardened.
For the complete, itemised list see the canonical
CHANGELOG.md.
Version 0.11.0 (2026-06-10)
The backend module's default Configuration is now the single source of truth
for generic completion: chat(), complete() and streamChat() resolve
the active default database-backed configuration (provider adapter, model and
vault-backed credentials) when no provider is pinned, with per-call options
overriding the stored defaults. The extension-configuration defaultProvider
becomes a fallback for installations without a usable default configuration.
For the complete, itemised list see the canonical
CHANGELOG.md.
Added
Default-configuration routing for generic completion. Calls without a
pinned provider route through the module-managed default
LlmConfiguration; per-call ChatOptions override its stored
defaults. chatWithConfiguration() / completeWithConfiguration() /
streamChatWithConfiguration() accept an $optionOverrides array.
Changed
The extension-configuration defaultProvider is consulted only when no
usable default configuration exists. Defaults without a model, or with
backend-group access restrictions, are skipped — group-restricted
configurations are never auto-applied without a backend-user context.
Version 0.10.0 (2026-06-09)
The specialized AI services (DALL-E, FAL, Whisper, TTS, DeepL) now authenticate
through nr-vault's audited secure HTTP client instead of plaintext API keys,
bringing them in line with the database-backed providers (ADR-012, ADR-030).
For the complete, itemised list see the canonical
CHANGELOG.md.
Changed
Specialized services authenticate through nr-vault. Each service stores
an nr-vault secret identifier and authenticates via
$vault->http()->withAuthentication(...); the secret is resolved,
injected, audited, and memory-scrubbed inside the vault and never surfaces
in this extension. FAL (Authorization: Key …) and DeepL
(Authorization: DeepL-Auth-Key …) use the nr-vault 0.8.0 prefix
option. DeepL's Free/Pro routing stays automatic via a one-time, scrubbed
:fx suffix check.
Removed
Plaintext API keys for the specialized services. Configuration keys are
now nr-vault identifiers (providers.openai.apiKeyIdentifier,
image.fal.apiKeyIdentifier, translators.deepl.apiKeyIdentifier).
Requires netresearch/nr-vault ^0.8.0.
Version 0.9.0 (2026-06-08)
This release migrates image generation to OpenAI's gpt-image-\* model
family (DALL·E-3 was retired by OpenAI), makes chat JSON mode actually request
JSON, and corrects the empty base-URL handling of the specialized services.
For the complete, itemised list see the canonical
CHANGELOG.md.
Added
gpt-image-\* image generation.ImageGenerationOptions accepts the
gpt-image-* family by prefix and validates its size set
(1024x1024 / 1536x1024 / 1024x1536 / auto);
DallEImageService maps the family to a shared capability profile and
sends a minimal payload (gpt-image rejects response_format /
style / quality), reading the returned b64_json.
Fixed
Chat JSON mode.OpenAiProvider now maps response_format=json to
OpenAI's {"type":"json_object"} so CompletionService::completeJson()
receives valid JSON instead of prose.
Empty base URL. An empty ext_conf baseUrl for the DALL·E, FAL and
TTS services now falls back to the provider default instead of being used as
a scheme-less request URL.
Version 0.8.0 (2026-06-02)
This release adds usage analytics and turns on real cost tracking, and
completes the provider middleware pipeline that now powers fallback,
pre-flight budget enforcement, usage accounting, and response caching
around every provider call. It also migrates the domain API to typed
value objects.
For the complete, itemised list see the canonical
CHANGELOG.md.
Added
Usage Analytics dashboard. A new Admin Tools → LLM → Analytics
submodule with cost and request trends, breakdowns by provider, model,
and service, KPI tiles, and per-user usage against each user's monthly
budget. The Providers, Models, Configurations, and Tasks list views also
gained per-row Cost / Requests / Tokens (last 30 days) columns. See
Usage analytics.
Real cost tracking. Usage is now priced from the configured model
rates (prompt/completion token split), so the AI cost this month widget
and the dashboard show real figures instead of 0. The
tx_nrllm_service_usage table gained model and token-split columns
plus per-task attribution.
Automatic budget pre-flight. Completion, embedding, translation, and
vision requests are checked against the configured budget before the call
is made.
Changed
The domain API moved to typed value objects (chat messages, tool specs,
vision content, capability sets, provider options). The legacy
string/array options accessors are deprecated in favour of the typed
equivalents.
Requires netresearch/nr-vault^0.6.0.
Breaking
The legacy Model::CAPABILITY_* class constants have been removed
in favour of the ModelCapability backed enum (for example
ModelCapability::CHAT->value). They had been deprecated since the enum
was introduced.
Version 0.7.0 (2026-04-22)
Added
Provider fallback chain.LlmConfiguration can now list
other configuration identifiers to retry against when the primary
fails with a retryable error (connection / HTTP 5xx / 429 rate-
limit). Non-retryable errors (4xx other than 429, configuration
problems, unsupported feature) bubble up unchanged. Streaming is
intentionally excluded from fallback because chunks cannot be
replayed against a different provider. See ADR-021: Provider Fallback Chain and
Fallback chain.
Attribute-based provider registration. New
#[AsLlmProvider(priority: N)] attribute. Providers bearing
the attribute are automatically tagged and made public by
ProviderCompilerPass at container compile time; no
services.yaml edit required. Legacy yaml tagging still works
for third-party providers and takes precedence when both
mechanisms are present. See ADR-022: Attribute-Based Provider Registration and
Registering a provider.
Per-capability BE group permissions. Every
ModelCapability enum value is now a native TYPO3
customPermOptions entry under the nrllm namespace. BE
group editors see a checkbox per capability (chat, completion,
embeddings, vision, streaming, tools, json_mode, audio). New
CapabilityPermissionService resolves checks against the
current BE user with admin short-circuit and CLI / frontend
bypass. See ADR-023: Native Backend Capability Permissions and BE group permission checks.
Dashboard widgets. Two TYPO3 dashboard widgets sourced from
tx_nrllm_service_usage: AI cost this month
(NumberWithIconWidget) and AI requests by provider (7d)
(BarChartWidget). Loaded conditionally from
Configuration/Services.php only when
typo3/cms-dashboard
is installed. See ADR-024: Dashboard Widgets.
Per-user AI budgets. New tx_nrllm_user_budget table
with six independent ceilings (requests / tokens / cost × daily /
monthly). New BudgetService::check() aggregates usage on
demand from tx_nrllm_service_usage — one DB roundtrip for
both windows via conditional SUM(). Orthogonal to the
existing per-configuration daily limits: both checks must pass.
See ADR-025: Per-User AI Budgets and Per-user AI budgets.
Changed
CI: mutation testing runs only on push, merge_group and
schedule events. PR CI gets the fuzz suite + unit / functional
/ PHPStan / rector / code style; the 15 min mutation job is
deferred because its per-PR signal is hard for authors to action
locally.
CI: .semgrepignore added to exclude Tests/,
Build/Scripts/ and vendor directories from Opengrep SAST.
Previously failing on legitimate unlink() fixture cleanup.
CI: fuzz workflow now invoked with
fuzz-testsuite: fuzzy matching the phpunit.xml suite name.
Version 0.6.0 (2026-03-24)
Added
DocumentCapableInterface: providers can now advertise
PDF/document support; ChatCapabilitiesInterface exposes
this via getProviderCapabilities().
Multimodal content arrays in chatCompletion: pass images,
PDFs, and text blocks as structured content arrays alongside
regular string messages.
Tool message conversion: tool_result blocks are now mapped
correctly when assembling provider payloads.
Changed
Migrated CI infrastructure to netresearch/typo3-ci-workflows
shared workflows (PHP tests, docs, E2E).
Replaced GrumPHP with CaptainHook for pre-commit hooks.
Fixed
PHPStan baseline regenerated; ignoreErrors patterns
broadened for deprecation and array function rules to handle
phpstan-typo3 v2/v3 parameter name differences.