TYPO3 LLM extension

- Extension key
-
nr_llm
- Package name
- Version
-
0.7
- Language
-
en
- Author
-
Netresearch DTT GmbH
- License
-
This document is published under the CC BY 4.0 license.
- Rendered
-
Wed, 22 Apr 2026 13:39:10 +0000
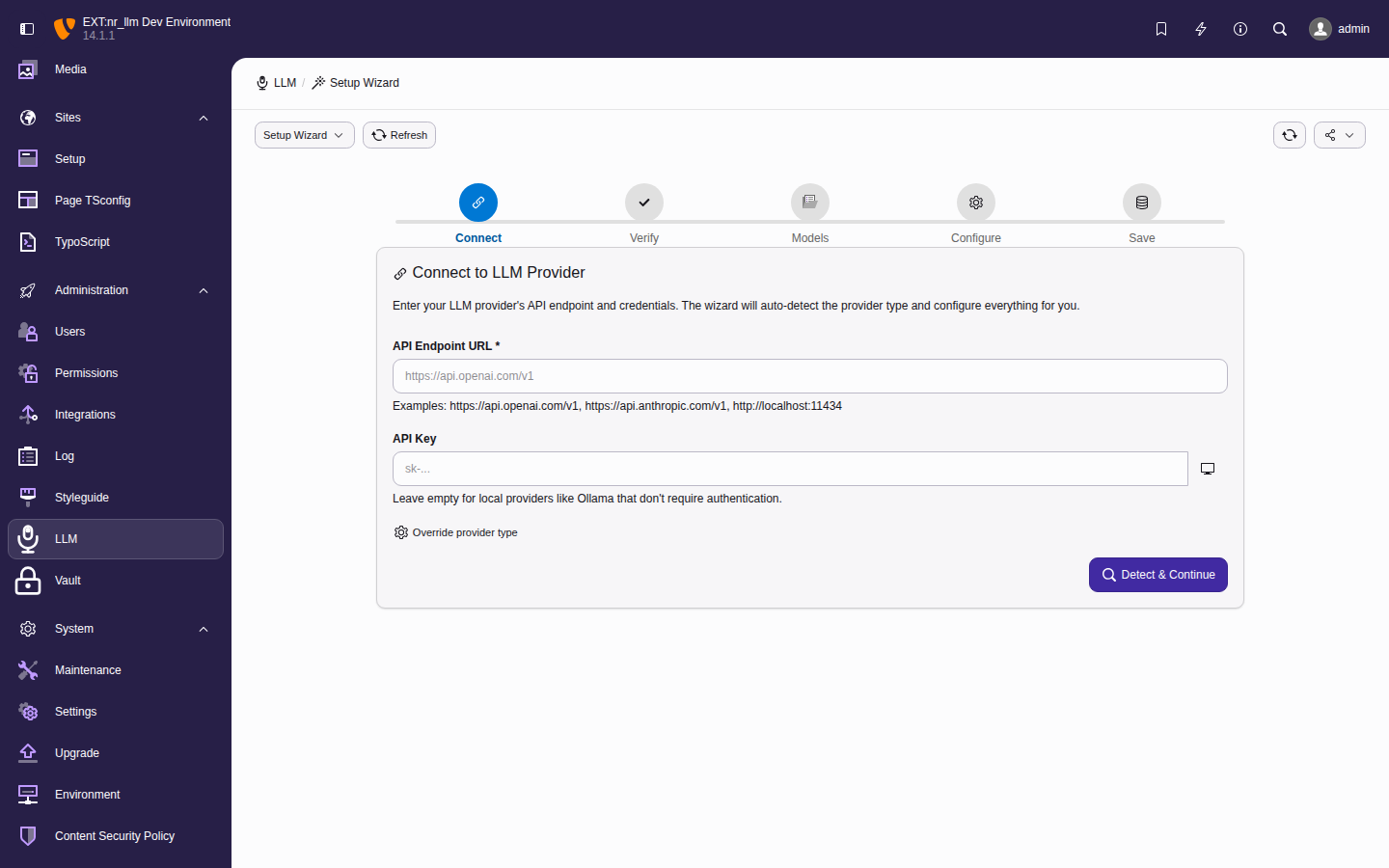
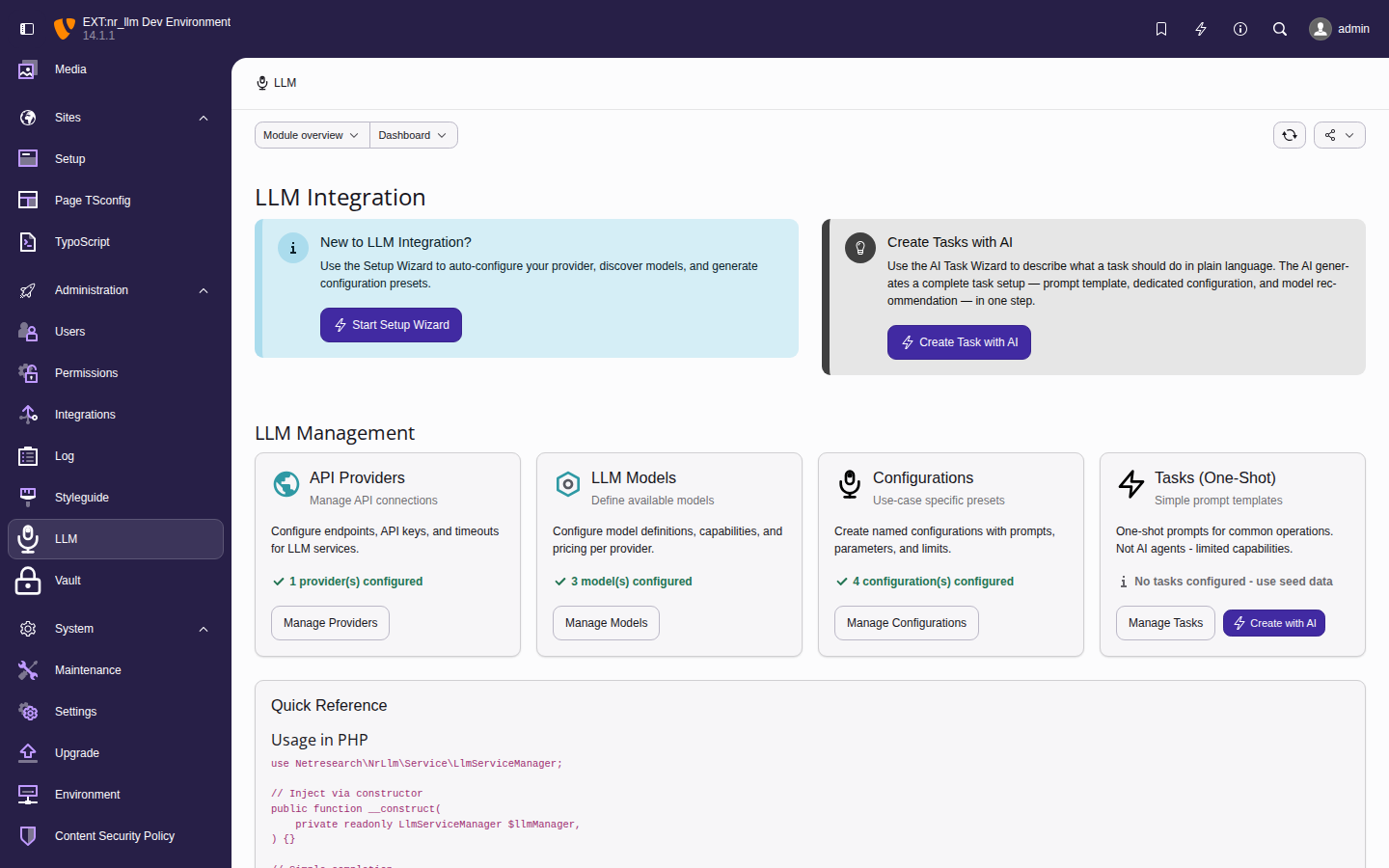
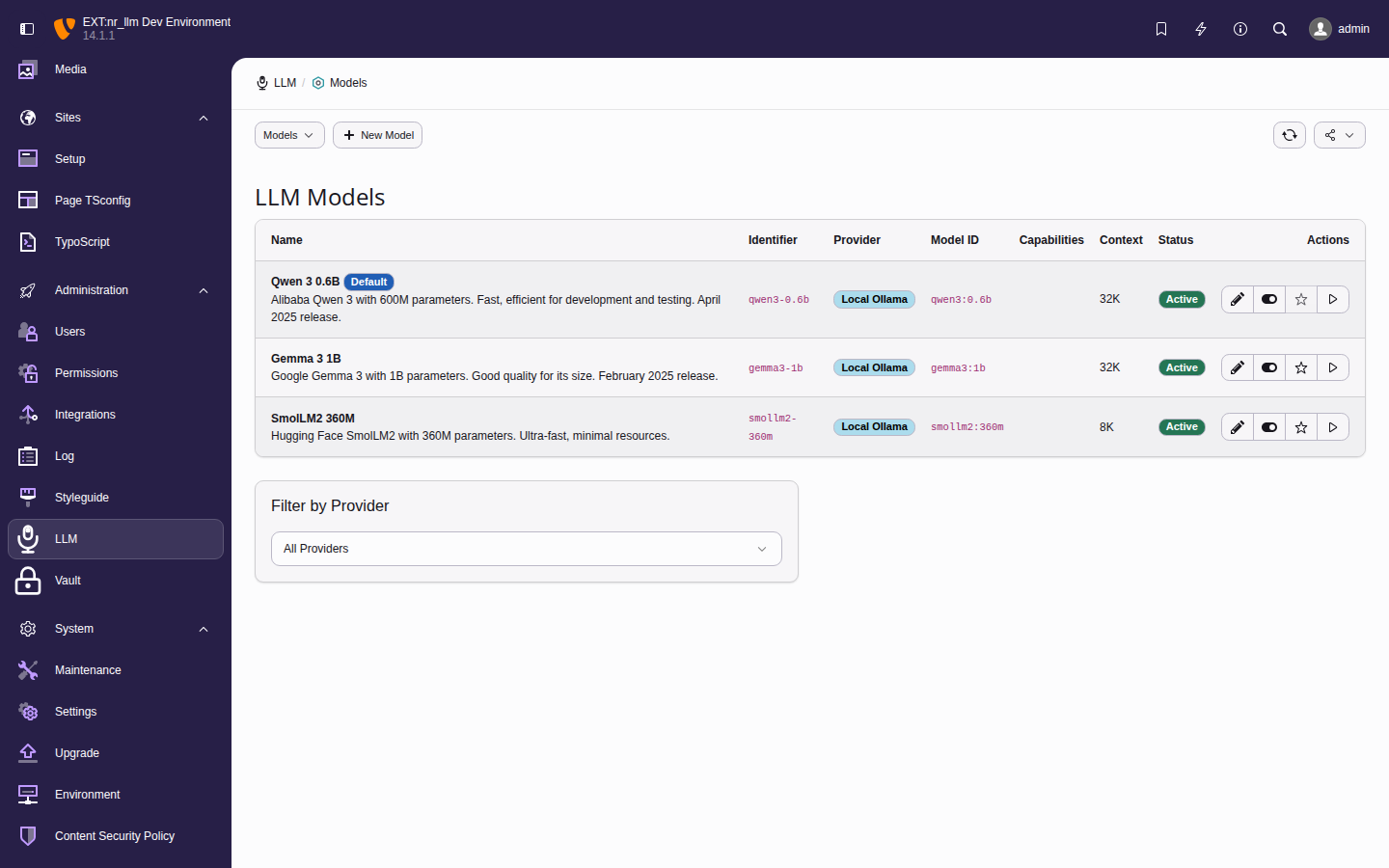
Shared AI foundation for TYPO3. Configure LLM providers once — every AI extension uses them. Supports OpenAI, Anthropic Claude, Google Gemini, Ollama, and more.

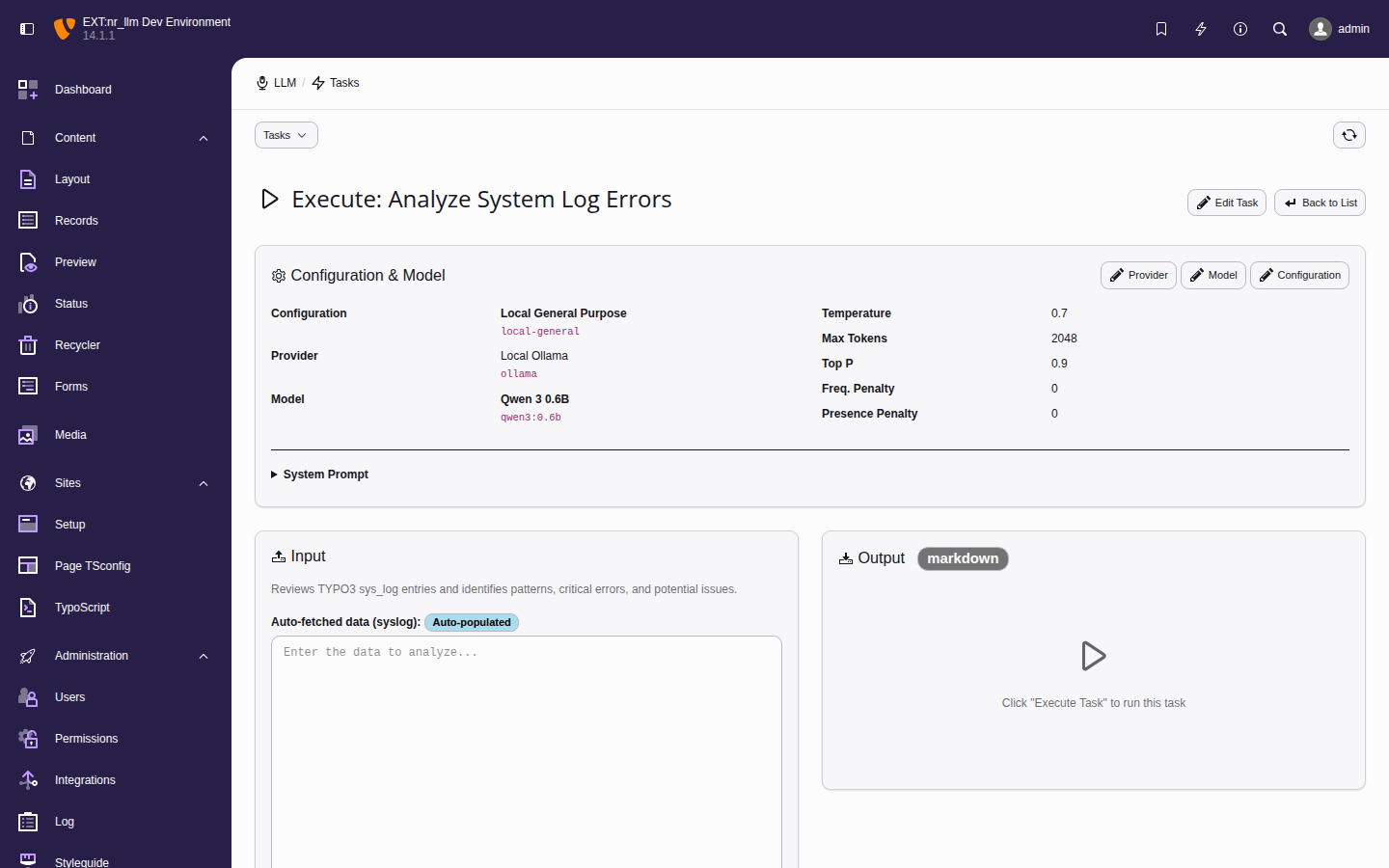
The Admin Tools > LLM backend module.
Getting started
For administrators
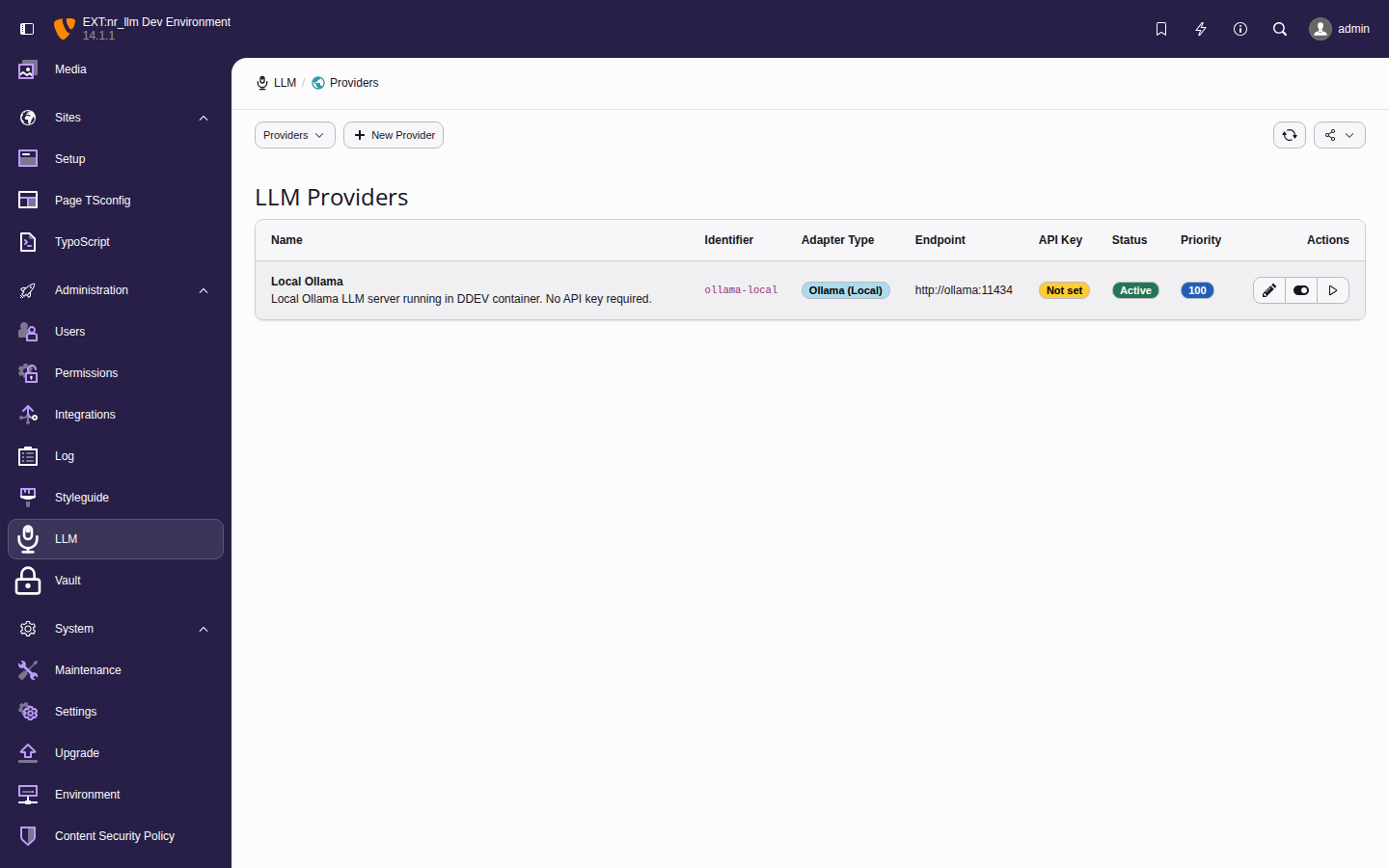
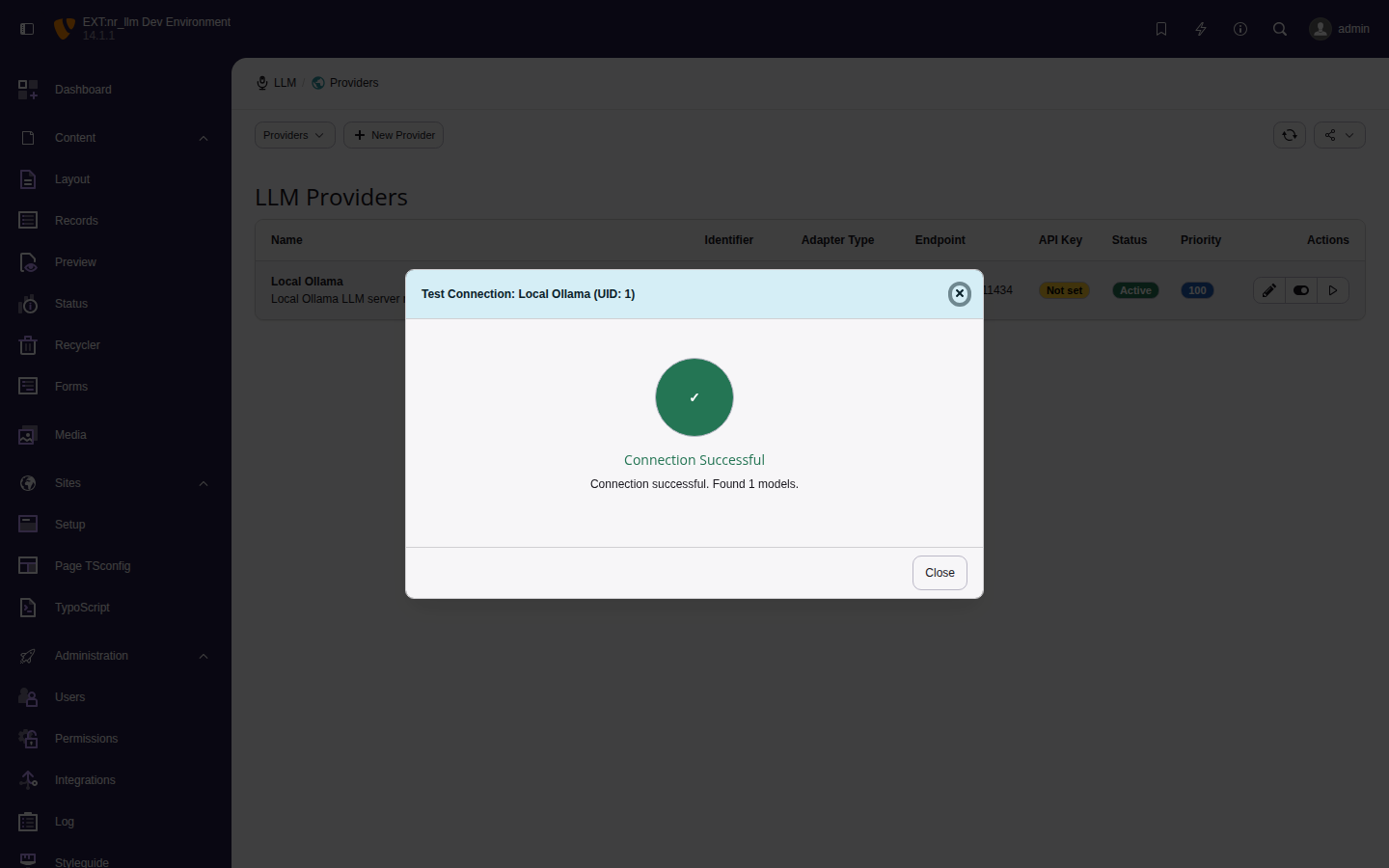
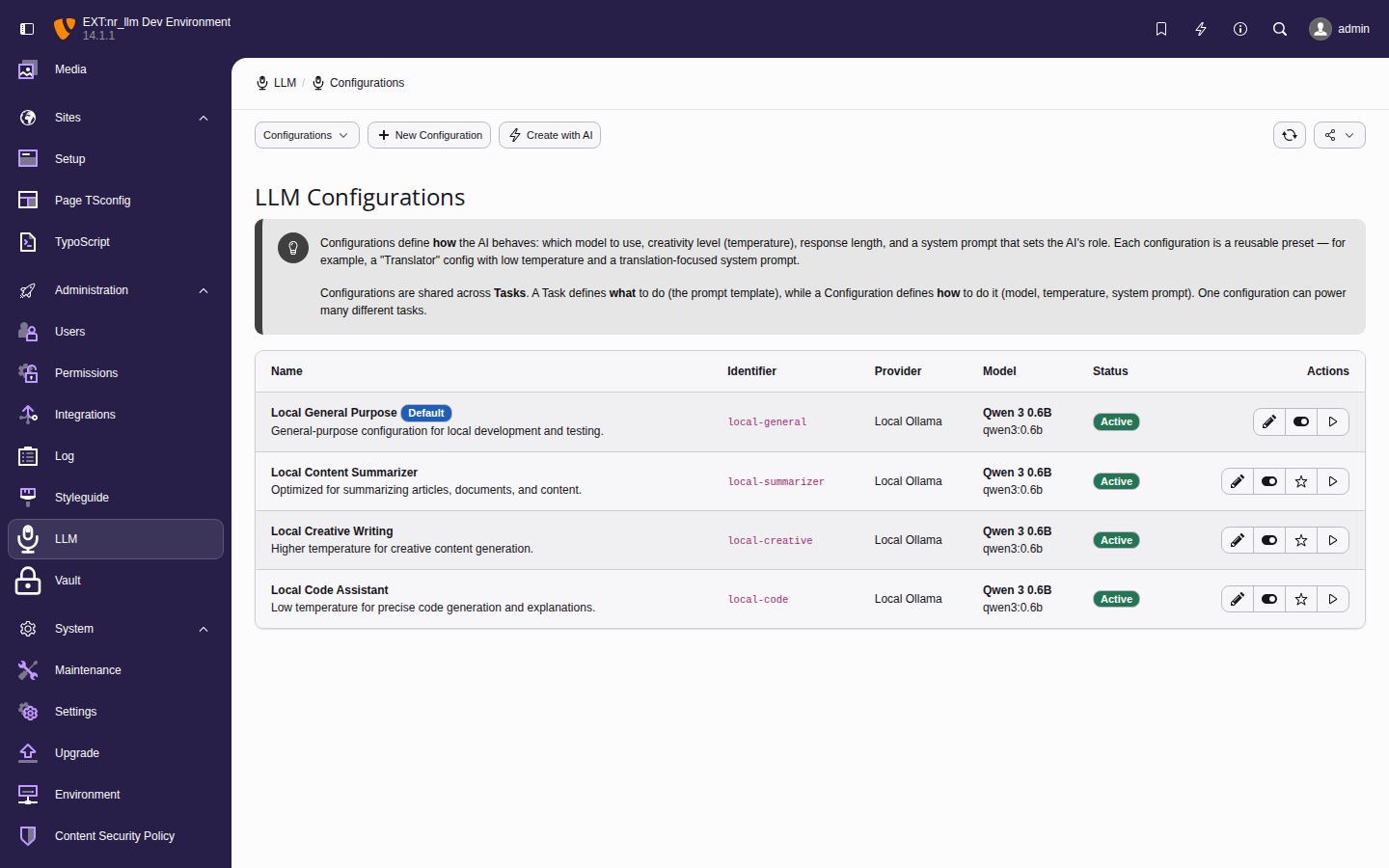
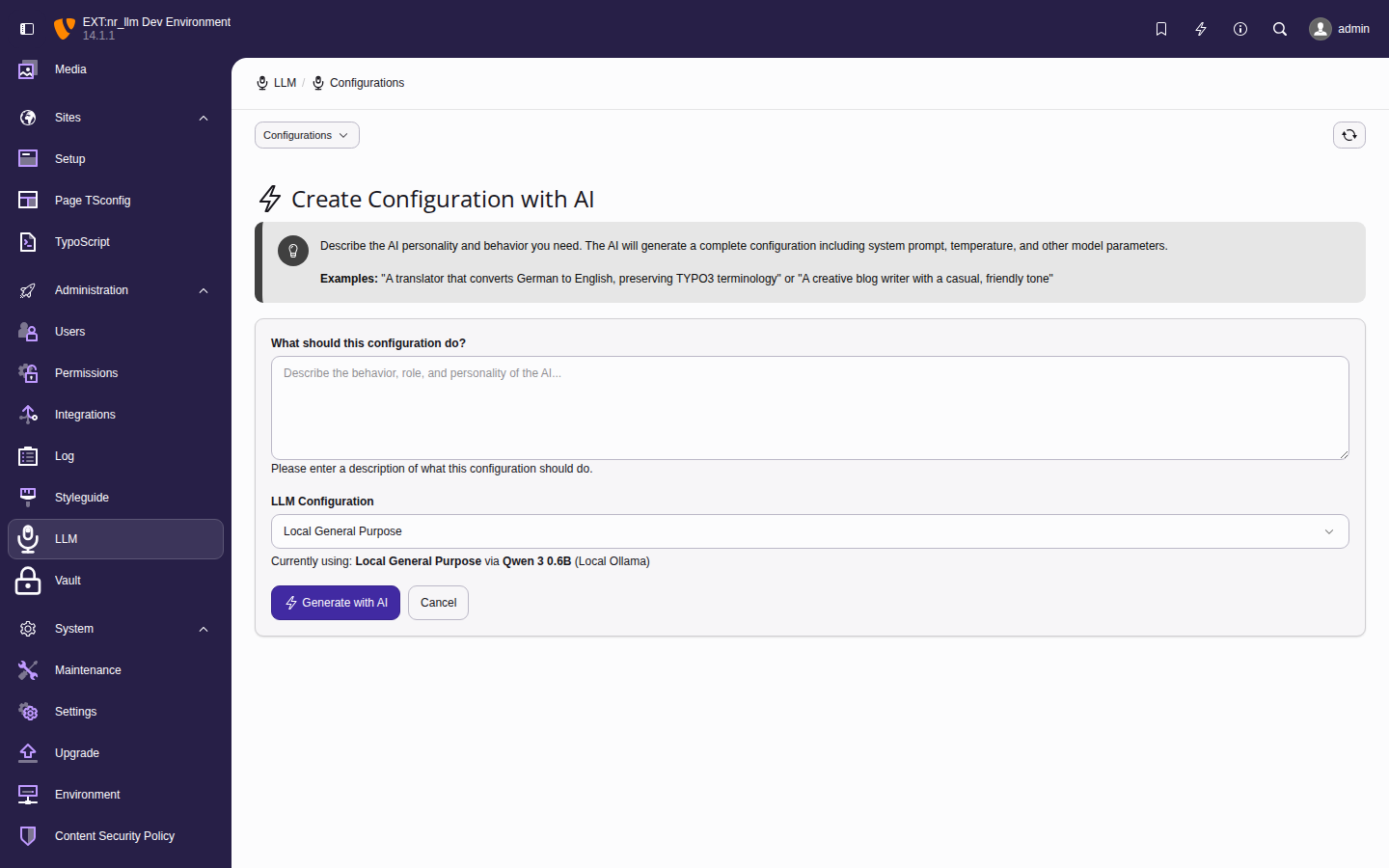
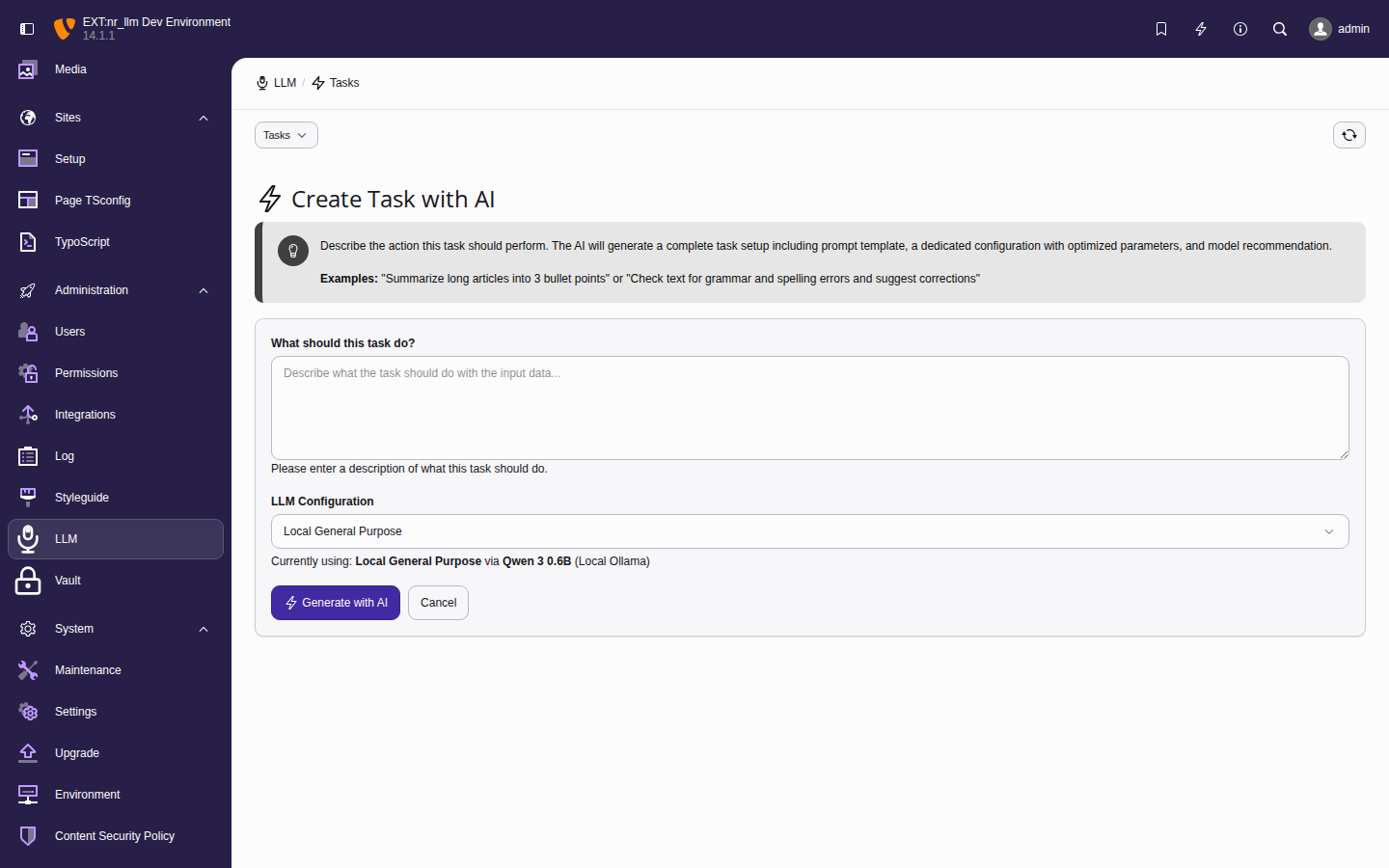
Set up and manage AI providers, models, and configurations through the TYPO3 backend module.
For developers
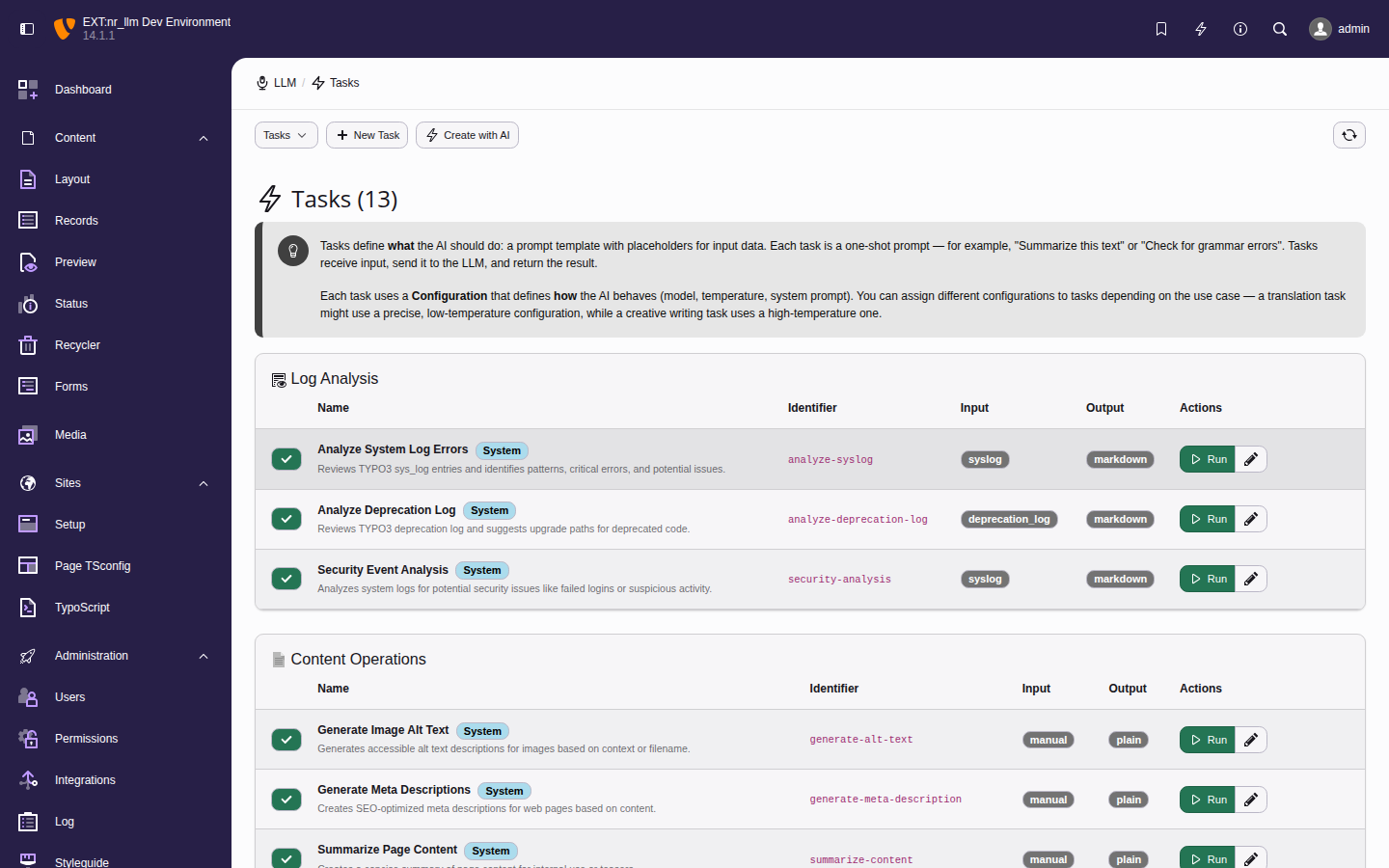
Build your TYPO3 extension on nr-llm — three lines of dependency injection, no API key handling.
Table of contents