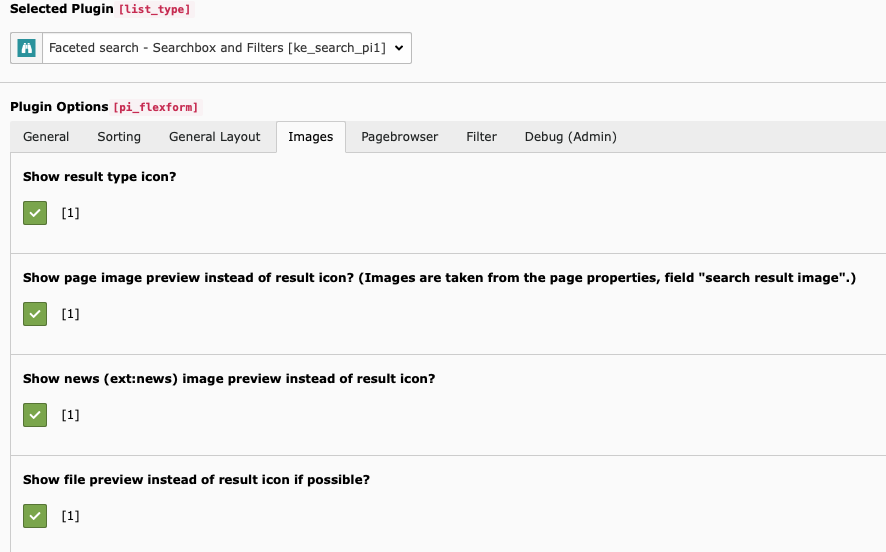
Content Elements
The content element indexer is much like the pages indexer with one important difference: The content element indexer
allows you to index single content element and every content element will be written to a single entry in the index.
That means you will be able to directly point the visitor to the matching content element but on the other side, you
will have multiple index entries for one page.
In most cases, the pages indexer is more suitable than the content element indexer because in most cases you only
want to have one index record per page.
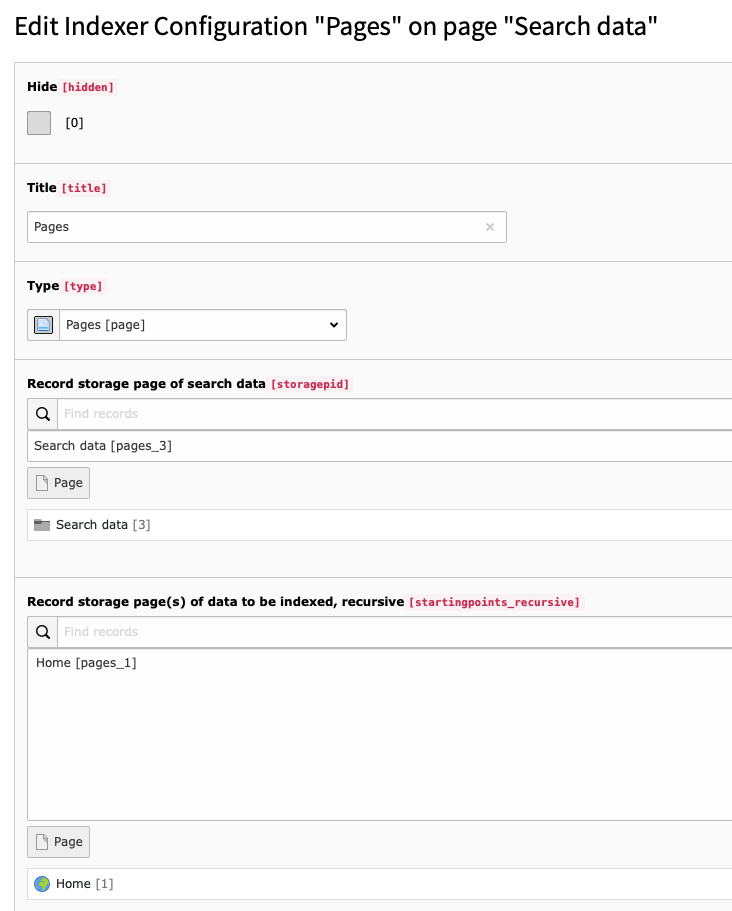
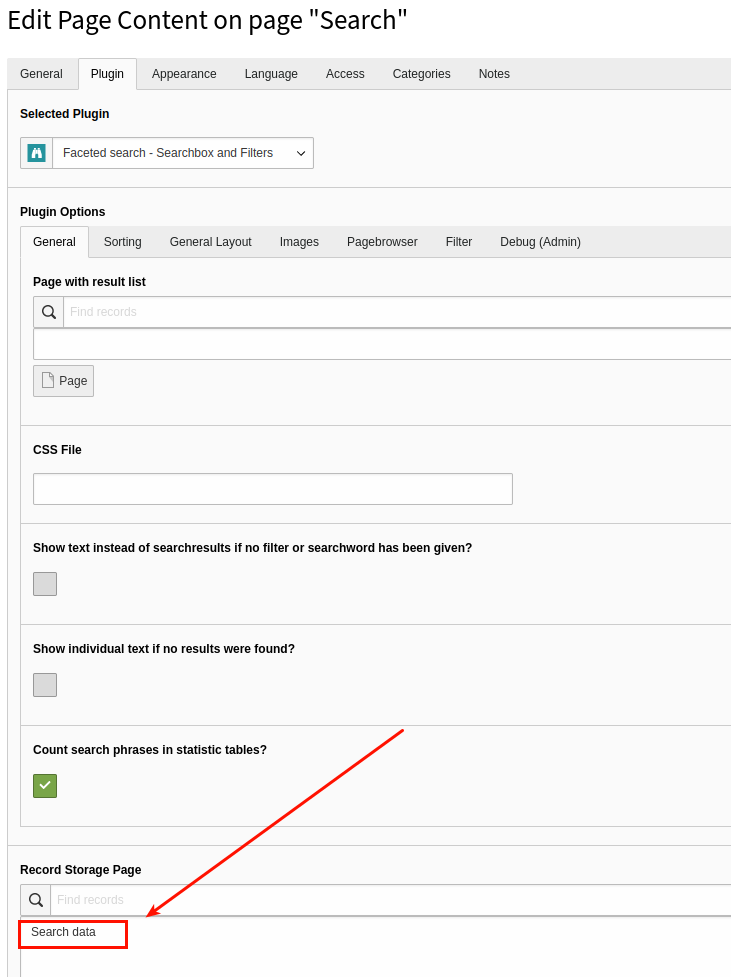
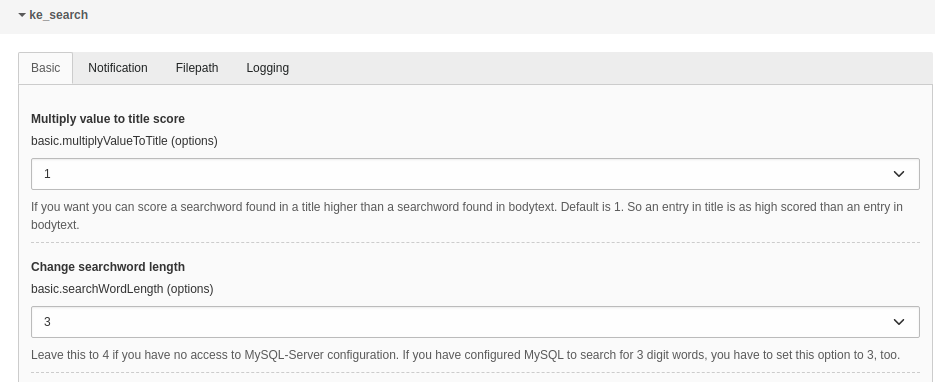
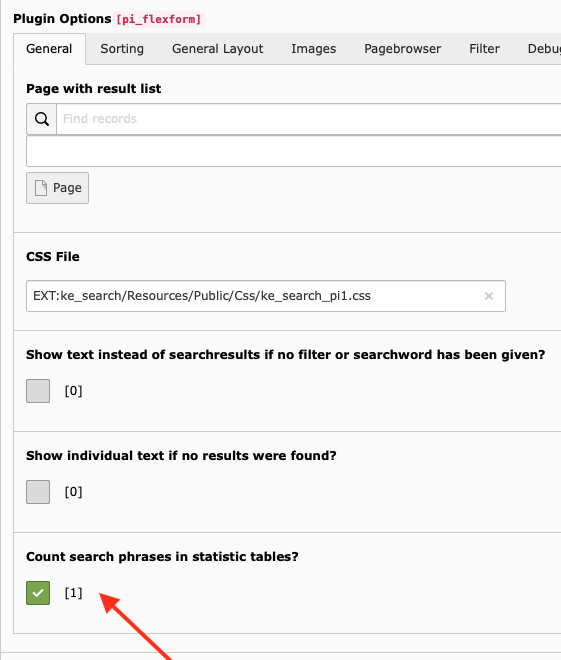
The content element indexer can be configured in the same way as the pages indexer.
The access restrictions for content elements are fully taken into account (see pages indexer).
Every content element inherits the access restrictions from the page it belongs to!
Note
There's another important difference:
Indexing your content on element basis instead of page basis means on the one hand you will get two results
if you have two text elements containing your search word on one page, which may be unwanted in most cases.
On the other hand, all access restrictions are taken fully into account, while by using the pages indexer only the
page access restrictions will be taken into account, not the content element access restrictions.
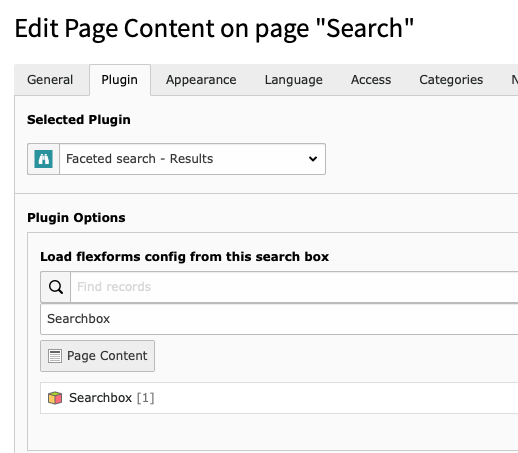
In the result list, the result will link to the content element directly (via an anchor link).