Executing queue with cron-job
A "cron-job" refers to a script that runs on the server with time intervals.
For this to become reality you must ideally have a cron-job set up.
This assumes you are running on Unix architecture of some sort. The
crontab is often edited by
crontab - and you should insert a line
like this:
* * * * * vendor/bin/typo3 crawler:buildQueue <startpage> <configurationKeys> > /dev/nullThis will run the script every minute. You should try to run the script on the command line first to make sure it runs without any errors. If it doesn't output anything it was successful.
You will need to have a user called _cli_ and you must have PHP installed
as a CGI script as well in /usr/.
The user _cli_ is created by the framework on demand if it does not exist
at the first command line call.
Make sure that the user _cli_ has admin-rights.
In the CLI status menu of the Site Crawler info module you can see the status:
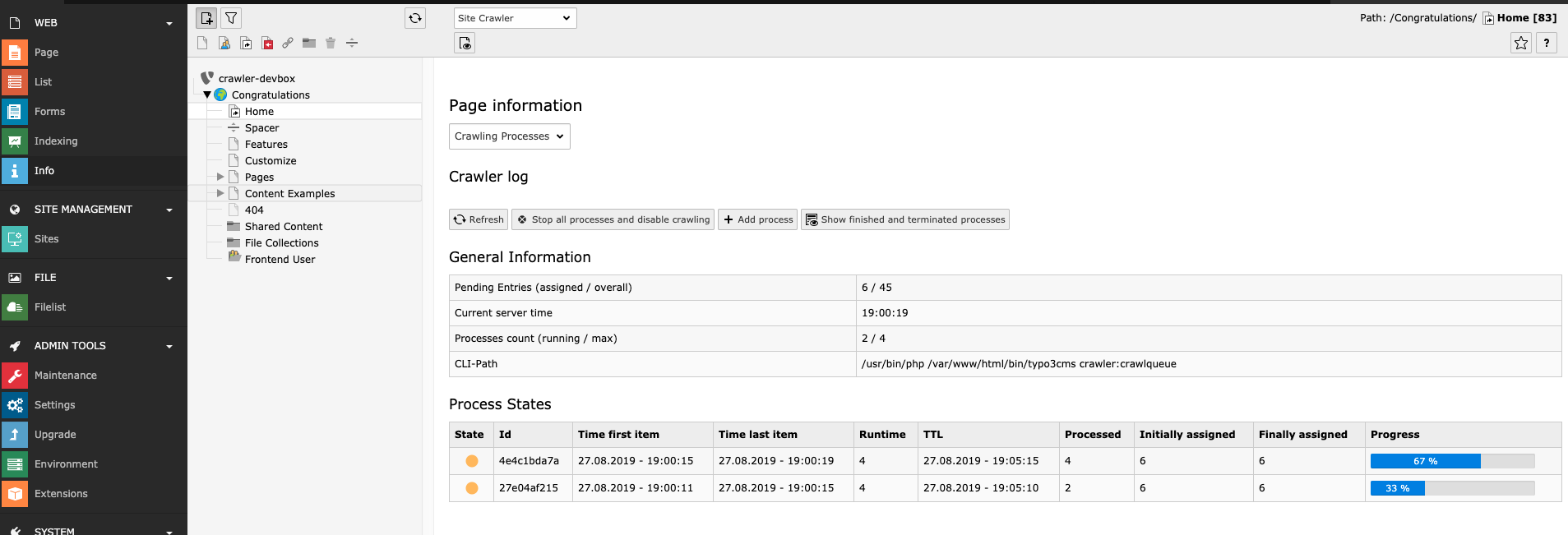
Status page in the backend
This is how it looks just after you ran the script. (You can also see the full path to the script in the bottom - this is the path to the script as you should use it on the command line / in the crontab)
If the cron-script stalls there is a default delay of 1 hour before a new process will announce the old one dead and run a new one. If a cron-script takes more than 1 minute and thereby overlaps the next process, the next process will NOT start if it sees that the "lock- file" exists (unless that hour has passed).
The reason why it works like this is to make sure that overlapping calls to the crawler CLI script will not run parallel processes. So the second call will just exit if it finds in the status file that the process is already running. But of course a crashed script will fail to set the status to "end" and hence this situation can occur.